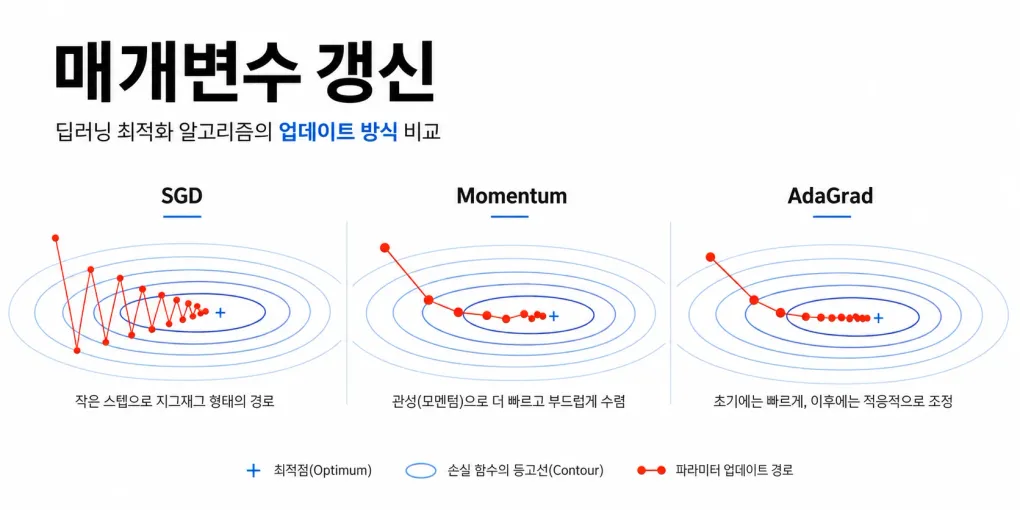
정의
매개변수 갱신(Parameter Update)은 손실 함수의 값을 줄이기 위해 신경망의 가중치와 편향을 반복적으로 수정하는 과정이다.
신경망은 역전파를 통해 각 매개변수에 대한 기울기를 구하고, 이 기울기를 이용해 매개변수를 어느 방향으로 얼마나 이동시킬지 결정한다.
가장 기본적인 방법은 SGD(확률적 경사하강법)이지만, SGD는 함수의 형태에 따라 비효율적인 탐색 경로를 보일 수 있다. 이를 개선하기 위해 Momentum, AdaGrad 같은 최적화 기법을 사용한다.
SGD와 Momentum
SGD(Stochastic Gradient Descent)는 현재 위치에서의 기울기를 따라 매개변수를 갱신하는 방법이다.
기본적인 갱신 식은 다음과 같다.
여기서 는 학습률이고, 는 손실 함수 을 가중치 에 대해 미분한 기울기이다.
SGD의 단점
SGD는 단순하고 직관적이지만 다음과 같은 단점이 있다.
- 기울기가 바뀌면 급격하게 방향 전환이 이루어지며 진동하는 현상이 발생한다.
- 비등방성 함수처럼 방향에 따라 기울기가 다른 경우 탐색 경로가 비효율적이다.
예를 들어 다음 함수를 생각해보자.
이 함수는 방향과 방향에서의 기울기가 서로 다른 비등방성 함수이다.
기울기는 다음과 같다.
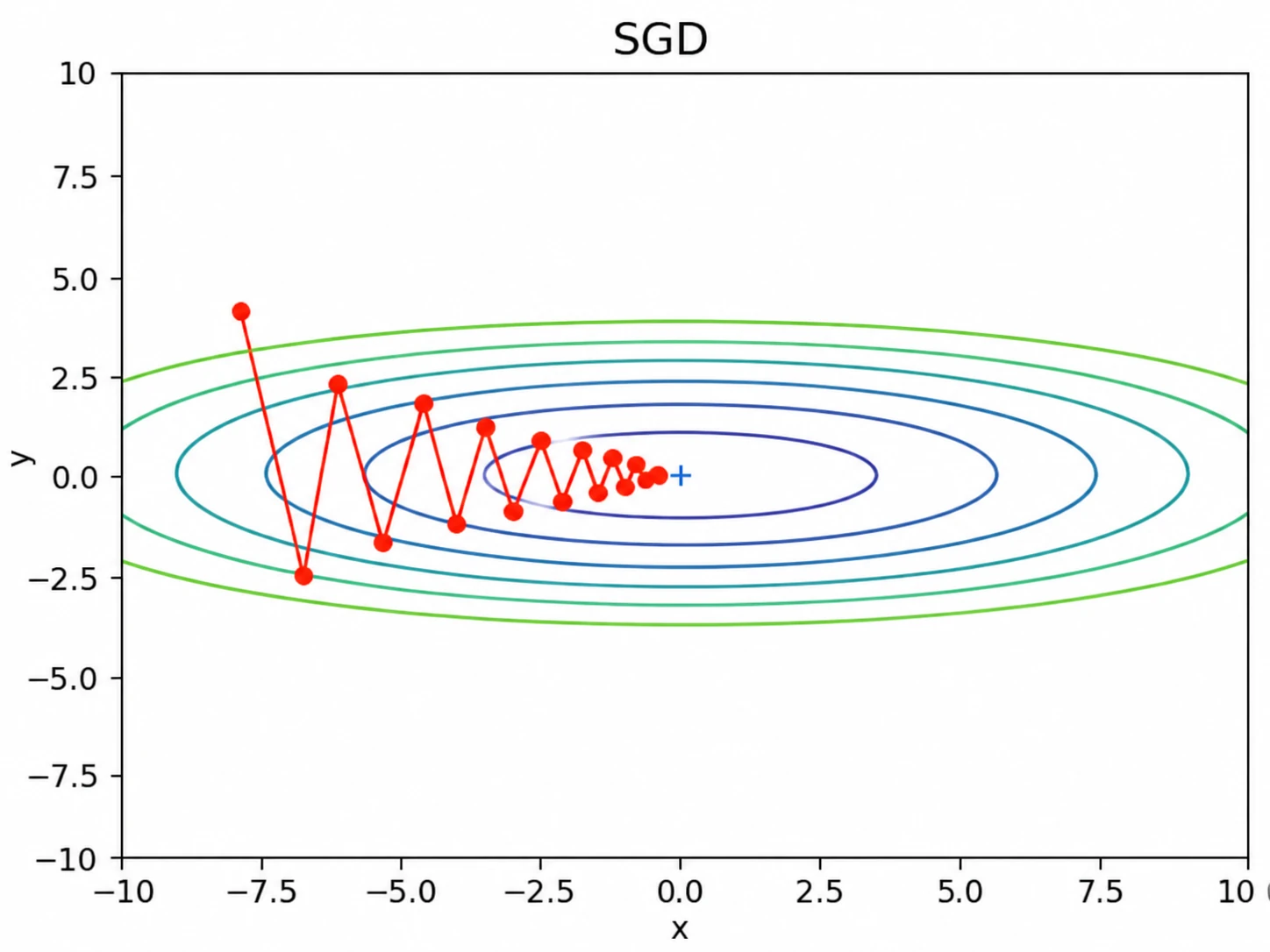
이처럼 방향에 따라 기울기의 크기가 크게 다르면, SGD는 최솟값을 향해 곧장 이동하지 못하고 진동하면서 이동할 수 있다.
Momentum 경사하강법
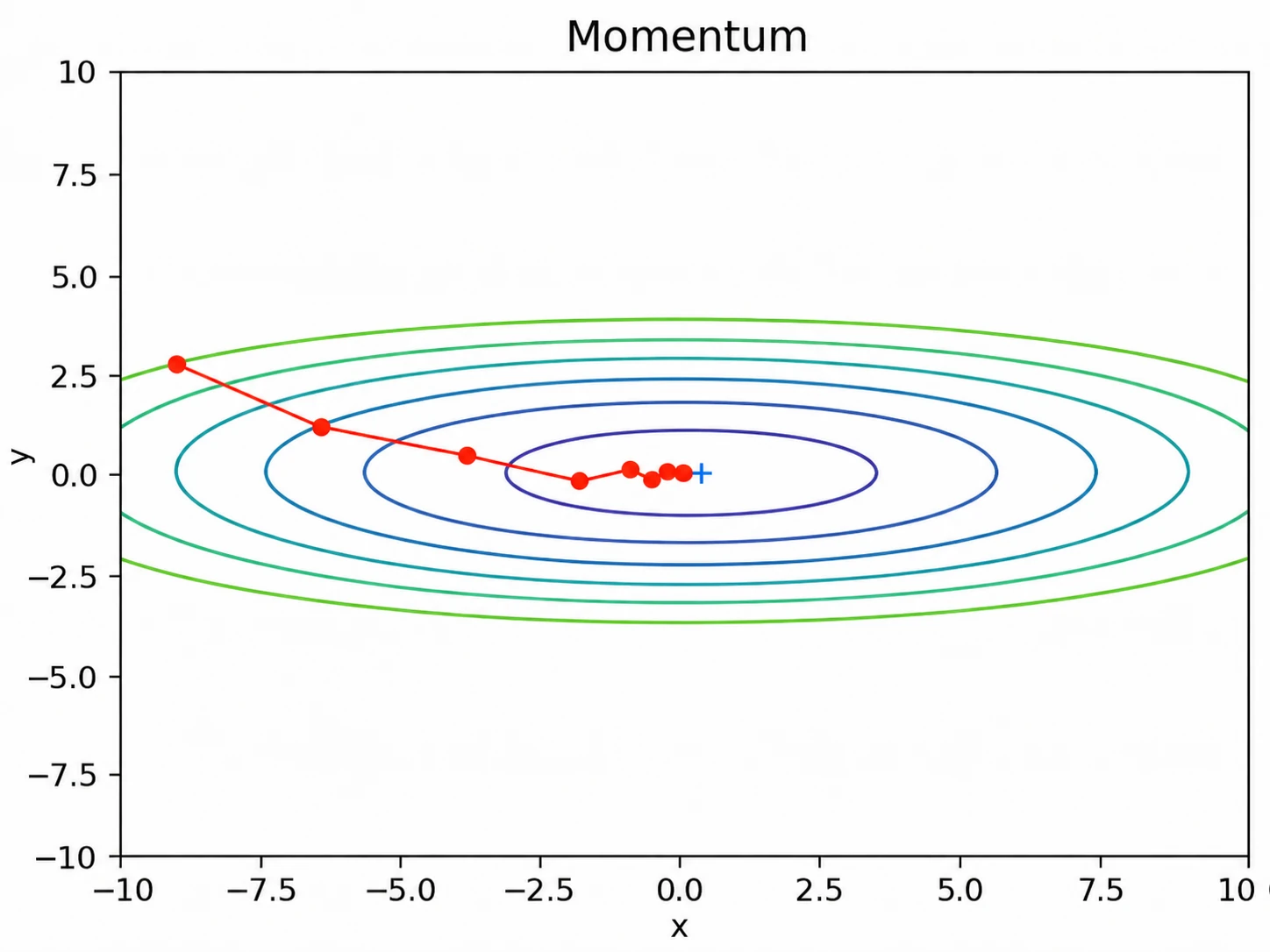
Momentum은 현재 기울기만 사용하는 것이 아니라, 이전 이동 방향의 관성을 함께 사용하는 방법이다.
갱신 식은 다음과 같다.
여기서 는 속도, 는 관성의 정도를 나타내는 계수이다. 보통 같은 값을 사용한다.
Momentum은 가중치 에 기울기를 바로 반영하지 않고, 를 통해 이전 이동 방향의 관성을 유지한다.
예를 들어 기울기가 바뀌는 지점에서 SGD는 즉각적으로 방향을 전환한다. 이 과정에서 진동 현상이 발생할 수 있다.
반면 Momentum은 이전 속도 를 유지한다. 따라서 기울기가 반대 방향으로 바뀌더라도 이동 방향이 즉시 반전되지 않고, 속도가 점차 줄어들다가 방향이 바뀐다.
직관적으로는 내리막길에서 공을 굴리다가 오르막길을 만나는 상황과 비슷하다. 공은 오르막길을 만난 순간 바로 반대 방향으로 튀지 않고, 기존 운동 방향을 유지하다가 속도가 0이 되는 시점 이후에 진행 방향이 전환된다.
Momentum 계산 예시
다음은 에서 Momentum을 적용하는 예시이다.
| Step | New | New | |||||
|---|---|---|---|---|---|---|---|
| 0 | -7.0 | 2.0 | 0 | 0 | -7.0 | 2.0 | |
| 1 | -7.0 | 2.0 | 0.07 | -0.4 | -6.93 | 1.6 | |
| 2 | -6.93 | 1.6 | 0.1337 | -0.72 | -6.796 | 0.88 | |
| 3 | -6.796 | 0.88 | 0.1874 | -0.884 | -6.609 | -0.004 | |
| 4 | -6.609 | -0.004 | 0.2348 | -0.7952 | -6.374 | -0.799 |
이 예시에서 방향은 기울기가 크게 변하기 때문에 SGD에서는 진동이 커지기 쉽다. Momentum은 이전 속도를 누적해 이동하므로 급격한 방향 전환을 줄이고 더 부드러운 경로를 만든다.
AdaGrad
AdaGrad(Adaptive Gradient)는 각 매개변수마다 학습률을 다르게 조정하는 방법이다.
기울기가 자주 크게 나타나는 매개변수는 학습률을 작게 만들고, 상대적으로 덜 갱신된 매개변수는 더 크게 움직일 수 있게 한다.
갱신 식은 다음과 같다.
여기서 는 기울기의 누적 제곱합이다. 는 요소별 곱(element-wise product), 즉 Hadamard product를 의미한다.
수식 분석
AdaGrad의 핵심은 지금까지의 기울기 제곱을 누적하는 것이다.
먼저 누적 기울기 제곱을 업데이트한다.
각 항의 의미는 다음과 같다.
- : 파라미터 에 대한 기울기의 누적 제곱합이다.
- : 요소별 곱이다.
- : 현재 손실 함수 에 대한 파라미터 의 기울기이다.
이 과정은 지금까지의 기울기 제곱들을 누적하는 과정이다.
그 다음 파라미터를 업데이트한다.
가 클수록 는 작아진다. 따라서 누적 기울기가 큰 매개변수는 학습률이 작아지고 업데이트 폭이 줄어든다.
즉, 어떤 파라미터 에 반복적으로 큰 기울기가 작용해 의 값이 커졌다면, AdaGrad는 해당 파라미터가 이미 많이 학습되었다고 판단하고 갱신 폭을 줄인다.
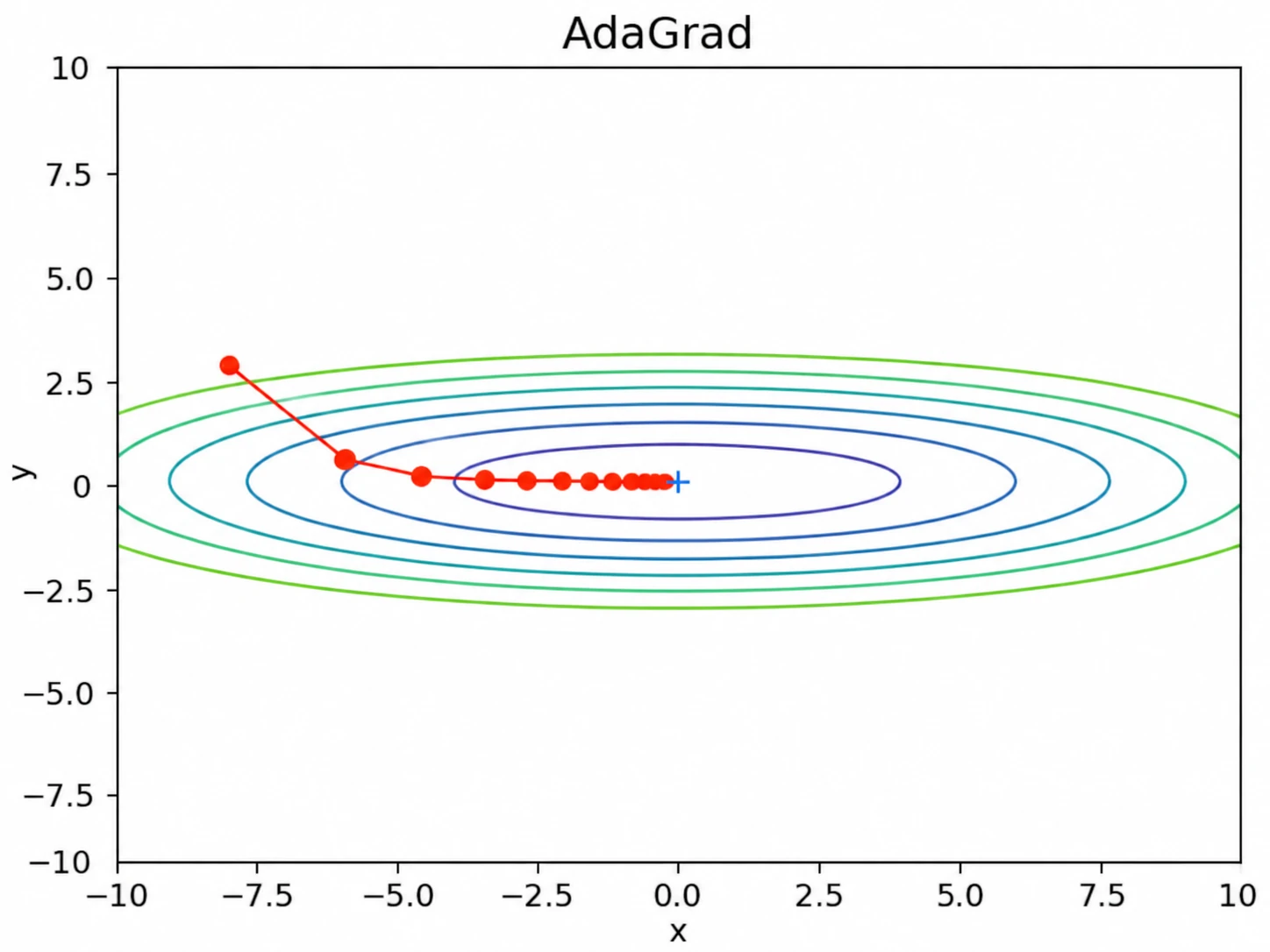
예를 들어 축 방향의 초기 기울기가 크다면 처음에는 크게 움직이지만, 누적 기울기 제곱합도 빠르게 커진다. 그 결과 축 방향의 갱신 정도가 큰 폭으로 작아지도록 조정된다.
즉, AdaGrad는 학습이 많이 진행된 방향의 학습률을 자동으로 줄여 비효율적인 진동을 완화한다.
정리
SGD는 현재 기울기만 이용해 매개변수를 갱신하는 가장 기본적인 방법이다. 하지만 비등방성 함수에서는 진동이 발생하며 탐색 경로가 비효율적일 수 있다.
Momentum은 이전 이동 방향의 관성을 사용하여 급격한 방향 전환을 줄이고 더 부드럽게 최솟값을 향해 이동한다.
AdaGrad는 각 매개변수의 누적 기울기 제곱합을 이용해 학습률을 자동으로 조정한다. 많이 움직인 방향은 학습률을 줄이고, 덜 움직인 방향은 상대적으로 크게 갱신한다.