
모든 가중치의 값이 동일한 경우
모든 가중치의 값이 동일하면 각 노드가 받는 기울기도 동일해진다.
이 경우 여러 노드를 가진 레이어를 사용하더라도 단일 노드 가중치 레이어와 큰 차이가 없어지고, 각 노드가 서로 다른 특징을 학습하지 못한다.
따라서 신경망이 정상적으로 다양성을 가지고 학습을 시작하려면 대칭성을 제거해야 한다. 가중치 초기화는 이 대칭성을 깨는 첫 단계이다.
표준편차가 1인 정규분포로 초기화하는 경우
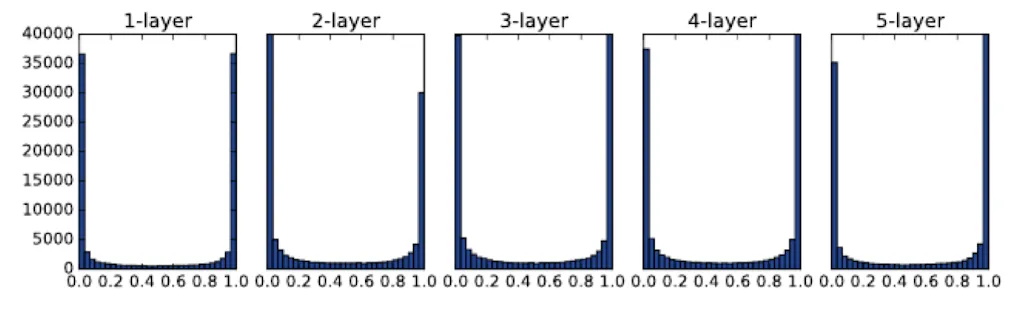
가중치를 표준편차가 1인 정규분포로 초기화하면 활성화값이 0 또는 1 부근에 몰릴 수 있다.
비선형 함수의 출력이 특정 구간에 치우치면 미분값이 작아지고, 역전파 시 기울기가 거의 0에 가까워진다. 그 결과 학습이 정체된다.
예를 들어 Sigmoid 함수를 생각해보자.
Sigmoid 함수는 다음과 같다.
실수 전체 범위에서 가 커지면 출력은 1에 가까워지고, 가 작아지면 출력은 0에 가까워진다.
시그모이드 함수의 미분은 다음과 같다.
가 0 또는 1에 가까우면 미분은 0에 수렴한다.
예를 들어 라면 다음과 같다.
결론적으로 활성화값들이 특정 값으로 치우치면 표현력이 제한된다. 또한 역전파 과정에서 전달되는 기울기도 작아져 학습이 어려워진다.
Xavier 초깃값
Xavier 초깃값의 목표는 신호의 분산이 층을 거치며 너무 커지거나 작아지지 않게 하는 것이다.
초기 가중치가 너무 크거나 작으면 기울기 폭발 또는 기울기 소실이 발생할 수 있다.
x = np.random.randn(1000, 100)
node_num = 100
hidden_layer_size = 5
activations = {}
for i in range(hidden_layer_size):
if i != 0:
x = activations[i - 1]
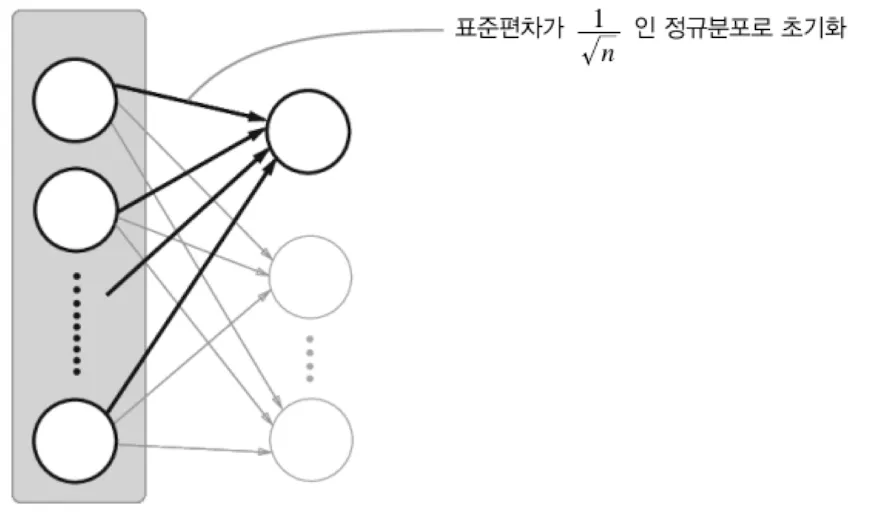
w = np.random.randn(node_num, node_num) / np.sqrt(node_num)
a = np.dot(x, w)
z = np.tanh(a)
activations[i] = zXavier 초기화의 접근법은 입력과 출력의 분산이 같도록 가중치를 초기화하는 것이다.
을 앞 계층 노드 수, 즉 입력 노드 수 이라고 하자.
출력 의 분산은 다음과 같이 볼 수 있다.
목표는 다음과 같다.
식을 정리하면 가중치의 표준편차는 다음과 같다.
즉, 가중치 분산은 다음과 같다.
Xavier 초기화에서 가중치 분산 양상
Xavier 초기화를 사용하면 앞층에 노드가 많을수록 대상 노드의 초깃값으로 설정되는 가중치가 좁게 퍼진다.
앞층 노드 수가 커지면 이 작아지므로 가중치들이 더 작고 좁은 범위로 초기화된다.
이유는 노드가 많아질수록 각 노드의 가중치를 줄여야 합산된 출력을 조절할 수 있기 때문이다.
수학적 직관
입력 노드 수를 , 각 입력 의 평균을 0, 분산을 라고 하자. 또한 가중치 도 평균이 0이고 분산이 라고 하자.
뉴런 출력은 다음과 같다.
이때 의 분산은 다음과 같다.
여기에는 개의 항이 존재한다. 목표는 출력 분산이 입력 분산과 비슷하게 유지되는 것이다.
즉, 신호 크기가 변하지 않도록 만드는 것이 목표이다.
목표를 달성하려면 다음 조건이 필요하다.
따라서 다음이 된다.
여기서는 직관을 위해 입력 노드 수 만 기준으로 작성했다.
실제 Xavier/Glorot 초기화는 전방 신호뿐 아니라 역전파되는 기울기의 분산도 함께 고려하기 위해 과 을 같이 사용하는 경우가 많다.
정규분포 기준으로는 보통 형태로 쓴다.
결론적으로 Xavier 초기화에서는 표준편차를 으로 설정한다. 이를 통해 출력 분산이 입력 분산과 같아지도록 하여 신호를 안정적으로 전달한다.
출력 분산과 입력 분산이 같으면 안정적인 이유
입력과 출력의 분산이 같으면 각 층을 통과할 때 신호의 크기, 즉 스케일이 유지된다.
신경망이 깊어져도 신호가 너무 작아지거나 커지지 않기 때문에 기울기 소실이나 폭발을 막고 학습을 원활하게 진행할 수 있다.
분산이 지속적으로 작아질 경우 다음 문제가 발생한다.
- 출력이 비선형 함수의 중심 근처에 몰린다.
- Sigmoid는 0.5 근처에 몰리고, Tanh는 0 근처에 몰린다.
- 각 뉴런의 출력이 비슷해지면서 표현의 다양성이 줄어든다.
- 층을 거치며 신호 스케일이 계속 작아져 역전파되는 기울기도 약해질 수 있다.
- 다만 Sigmoid와 Tanh의 도함수가 거의 0이 되는 대표적인 경우는 중심부가 아니라 포화 구간에 들어갔을 때이다.
분산이 지속적으로 커질 경우 다음 문제가 발생한다.
- 비선형 함수의 포화 구간 또는 ReLU 폭발 영역으로 진입한다.
- Sigmoid와 Tanh는 출력이 0 또는 1, 혹은 에 고정되어 도함수가 거의 0이 된다.
- ReLU는 출력값이 너무 커져 기울기 폭발이 발생할 수 있다.
- 결국 기울기 소실 또는 기울기 폭발이 발생한다.
ReLU 활성화 함수 사용 시
Xavier 초깃값은 활성화 함수가 특정 지점에서 선형이라고 볼 수 있는 경우에 잘 맞는다. 예를 들어 Sigmoid는 좌우대칭이고 중앙 부분에서는 거의 선형이라고 볼 수 있다.
반면 ReLU는 에서는 선형이지만, 전체 입력 중 약 절반은 0 이하에서 출력을 완전히 차단한다.
따라서 ReLU를 통과하면 출력 분산이 줄어든다. 이 경우 Xavier 초기화는 분산을 과소평가하게 되므로 He 초기화가 필요하다.
He 초기화
앞 계층 노드 수가 일 때, He 초기화는 표준편차를 다음과 같이 설정한다.
ReLU 함수는 다음과 같다.
직관적으로 Xavier 초기화는 을 사용하지만, ReLU에서는 음의 영역이 0이기 때문에 더 넓게 분포시키기 위해 2배의 계수를 사용한다고 볼 수 있다.
만약 Xavier 초기화처럼 으로 설정하면 ReLU를 거치면서 출력의 분산이 지속적으로 줄어든다.
레이어를 깊게 쌓으면 활성화 함수 통과 후의 분산이 계속 줄어들고, 역전파 시 기울기 소실이 발생할 수 있다.
이를 방지하기 위해 He 초기화는 분산에 2배 계수를 사용한다.
가중치 초기화 결론
가중치 초기화는 다음 흐름으로 이해할 수 있다.
- 표준정규분포 기반으로 Weight Tensor를 생성한다.
보통 다음과 같이 둔다.
- 표준편차 를 스칼라곱한다.
- 각 활성화 함수에 맞는 표준편차로 초기화한다.
예를 들어 ReLU에서는 He 초기화를 사용한다.
따라서 가중치는 다음 분포를 따른다.
정리
가중치를 모두 같은 값으로 초기화하면 대칭성이 깨지지 않아 노드들이 서로 다른 특징을 학습하지 못한다.
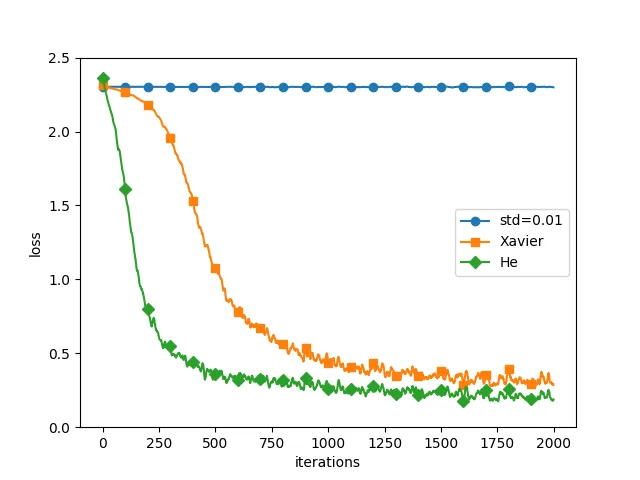
표준편차가 큰 정규분포로 초기화하면 활성화값이 포화 구간에 몰려 기울기 소실이 발생할 수 있다.
Xavier 초기화는 입력과 출력의 분산을 비슷하게 유지하여 신호를 안정적으로 전달하는 방법이다.
ReLU를 사용할 때는 음수 입력이 0으로 차단되기 때문에 Xavier 초기화보다 더 큰 분산을 사용하는 He 초기화가 적합하다.