정의
과대적합(Overfitting)은 신경망이 훈련 데이터에만 지나치게 적응되어, 처음 보는 데이터에는 제대로 대응하지 못하는 현상이다.
훈련 데이터에서는 높은 정확도를 보이지만 테스트 데이터에서는 성능이 낮아진다면 과대적합을 의심할 수 있다.
발생 상황
과대적합은 주로 다음 상황에서 발생한다.
- 매개변수가 많고 표현력이 높은 모델을 사용하는 경우
- 훈련 데이터가 적은 경우
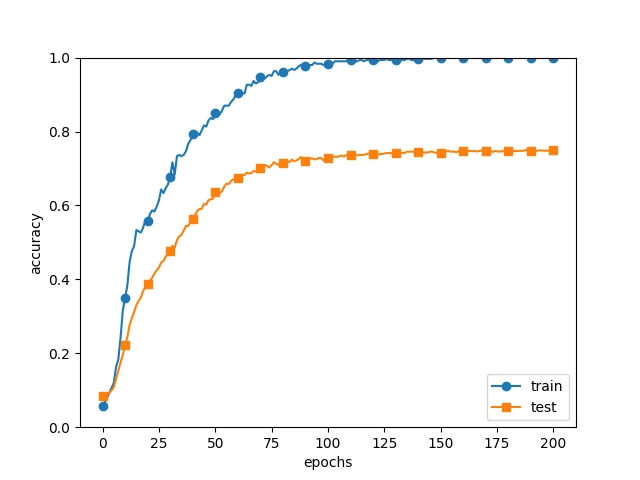
위 예시는 훈련 데이터를 300개로 제한한 경우에 발생한 과대적합이다. 모델이 훈련 데이터에는 지나치게 잘 맞지만, 테스트 데이터에는 일반화되지 못한다.
해결법
과대적합을 억제하는 대표적인 방법은 다음과 같다.
- 가중치 감소
- 드롭아웃
가중치 감소
가중치 감소(Weight Decay)는 학습 과정에서 큰 가중치에 대해 그에 상응하는 패널티를 부과하여 과대적합을 억제하는 방법이다.
과대적합은 일반적으로 가중치 매개변수 값이 커서 발생하는 경우가 많다. 가중치가 지나치게 커지면 출력이 커지고, 비선형 활성화 함수가 포화 구간에 들어가거나 결정 경계가 지나치게 복잡해질 수 있다.
즉, 모델이 데이터의 일반적인 패턴을 이해하는 대신 훈련 데이터만 단순히 암기하는 방향으로 학습될 수 있다.
신경망 학습의 기본 목적은 손실 함수의 값을 줄이는 것이다. 가중치 감소는 기존 손실 함수에 가중치 크기에 대한 패널티를 더한다.
예를 들어 가중치의 제곱 노름, 즉 L2 norm을 손실 함수에 더하여 가중치가 지나치게 커지는 것을 억제할 수 있다.
가중치 에 대해 L2 norm에 따른 가중치 감소 항은 다음과 같다.
여기서 는 정규화 세기를 조절하는 하이퍼파라미터이다. 를 크게 설정할수록 큰 가중치에 대한 패널티가 커진다.
는 미분 결과를 깔끔하게 만들기 위한 상수이다. 를 에 대해 미분하면 가 된다.
가중치 감소 직관
가중치 감소는 기존 손실 함수에 L2 정규화 항, 즉 패널티를 더하는 방식이다. L2 정규화 항은 하나의 스칼라값이다.
예를 들어 가중치 행렬이 다음과 같다고 하자.
이때 L2 norm은 다음과 같다.
일반적으로 행렬 에 대한 L2 norm은 다음과 같이 볼 수 있다.
여기서 는 노름을 의미한다. 노름은 벡터나 행렬 같은 다차원 객체의 크기를 측정하는 방법이다. L2 노름은 유클리드 거리와 연결된다.
가중치 감소를 적용하면 전체 손실 함수는 다음과 같다.
핵심은 역전파 과정에서 가중치 에 대해 미분할 때 가 추가된다는 점이다.
즉, 기존 gradient에 가 추가된다.
그 결과 가중치는 학습 중 자동으로 조금씩 줄어드는 방향으로 업데이트된다.
이를 정리하면 다음과 같다.
는 감쇠 계수이다. 이 항은 가중치를 조금 줄이는 역할을 한다.
이든 이든, 감쇠 계수는 가 0에 가까워지도록 크기를 줄인다. 부호는 유지하면서도 가중치 크기에 비례해 감소시키는 역할을 한다.
드롭아웃
드롭아웃(Dropout)은 훈련 시 무작위의 뉴런을 골라 삭제하는 방법이다.
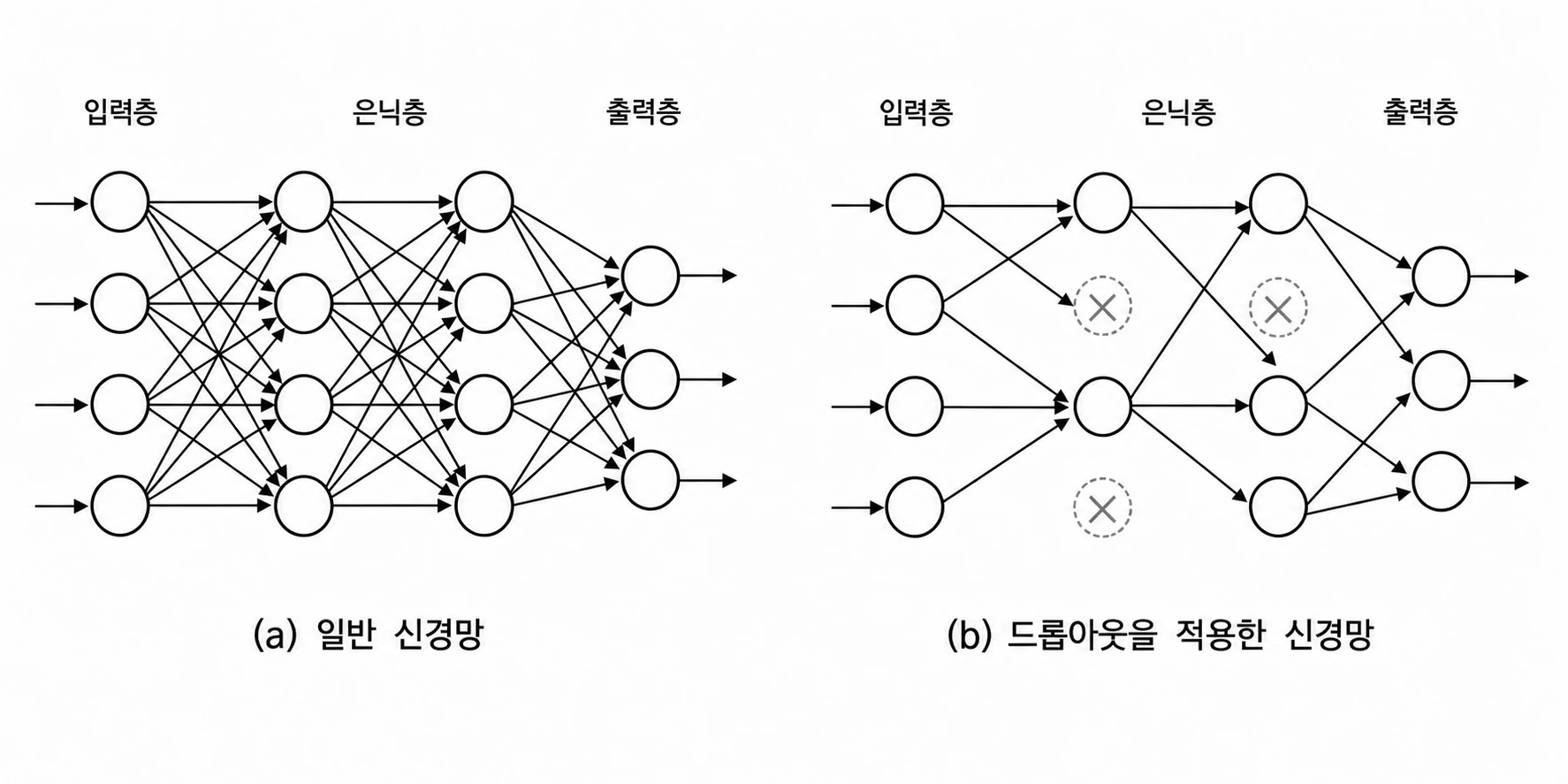
삭제된 뉴런은 신호를 전달하지 않는다.
훈련 시 데이터를 흘릴 때마다 삭제할 뉴런을 무작위로 선택한다. 시험 때는 모든 뉴런에 신호를 전달한다.
단, 시험 때는 모든 뉴런의 출력에 훈련 때 삭제하지 않은 비율을 곱하여 출력한다.
아래는 드롭아웃 구현 예시이다.
import numpy as np
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flag=True):
if train_flag:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask순전파 상황에서 훈련 중이라면, 사전에 설정된 확률값인 dropout_ratio에 따라 일부 뉴런을 False로 표시한다. 이 뉴런들은 ReLU처럼 신호를 그대로 통과시키거나, 신호를 죽여 0으로 만든다.
역전파에서도 Dropout으로 인해 꺼진 뉴런의 기울기는 0이 되어 전파되지 않는다.
드롭아웃 적용 결과

드롭아웃을 적용하면 훈련 데이터에만 과도하게 적응하는 현상이 줄어든다. 그 결과 훈련 데이터와 테스트 데이터 간의 성능 차이가 감소한다.
또한 훈련 데이터에서만 100% 정확도를 달성하는 과대적합 현상이 제거된다.
결과적으로 드롭아웃은 모델의 표현력을 유지하면서도 과대적합을 억제할 수 있는 방법이다.
드롭아웃과 앙상블 학습
앙상블 학습은 개별적으로 학습시킨 여러 모델의 평균 출력을 사용하는 방법이다.
드롭아웃은 매번 다른 뉴런 조합을 사용하기 때문에, 매번 다른 서브 네트워크를 학습하는 것으로 해석할 수 있다.
즉, 하나의 큰 네트워크 안에서 여러 서브 네트워크를 학습하고, 시험 시에는 이들의 평균적인 효과를 사용하는 것으로 볼 수 있다.
정리
과대적합은 모델이 훈련 데이터에 지나치게 맞춰져 새로운 데이터에 일반화하지 못하는 현상이다.
가중치 감소는 손실 함수에 가중치 크기에 대한 패널티를 추가하여 큰 가중치를 억제한다.
드롭아웃은 훈련 중 일부 뉴런을 무작위로 비활성화하여 특정 뉴런 조합에 지나치게 의존하지 않도록 만든다.
두 방법 모두 모델의 표현력을 유지하면서 일반화 성능을 높이기 위한 대표적인 정규화 기법이다.