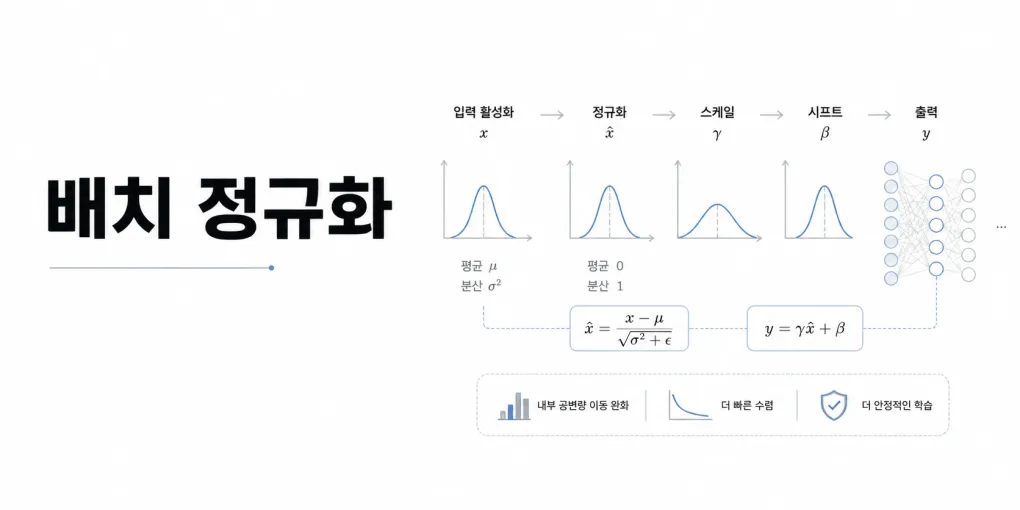
정의
배치 정규화(Batch Normalization, BN)는 딥러닝에서 학습을 안정적이고 빠르게 하기 위해 각 층의 출력을 정규화하는 기법이다.
각 층의 활성화값이 적당히 분포되도록 조정한다. 즉, 활성화값을 적당히 퍼뜨리도록 강제하여 분산이 너무 커지거나 작아지지 않게 유지한다.
왜 필요한가?
딥러닝 학습 중에는 이전 레이어의 파라미터가 계속 변한다. 따라서 각 층에 들어오는 값들의 분포도 매번 달라질 수 있다.
이 현상을 내부 공변량 변화(Internal Covariate Shift)라고 한다.
입력 분포가 계속 변하면 학습률을 높이기 어렵고, 학습이 느리고 불안정해진다.
배치 정규화는 미니배치 단위로 평균과 분산을 계산한 뒤 정규화하여, 각 층에 들어오는 값의 분포 변화를 완화한다.
배치 정규화의 장점
배치 정규화의 대표적인 장점은 다음과 같다.
- 학습 속도를 개선한다.
- 초깃값 의존도를 줄인다.
- 과대적합을 억제하는 효과가 있다.
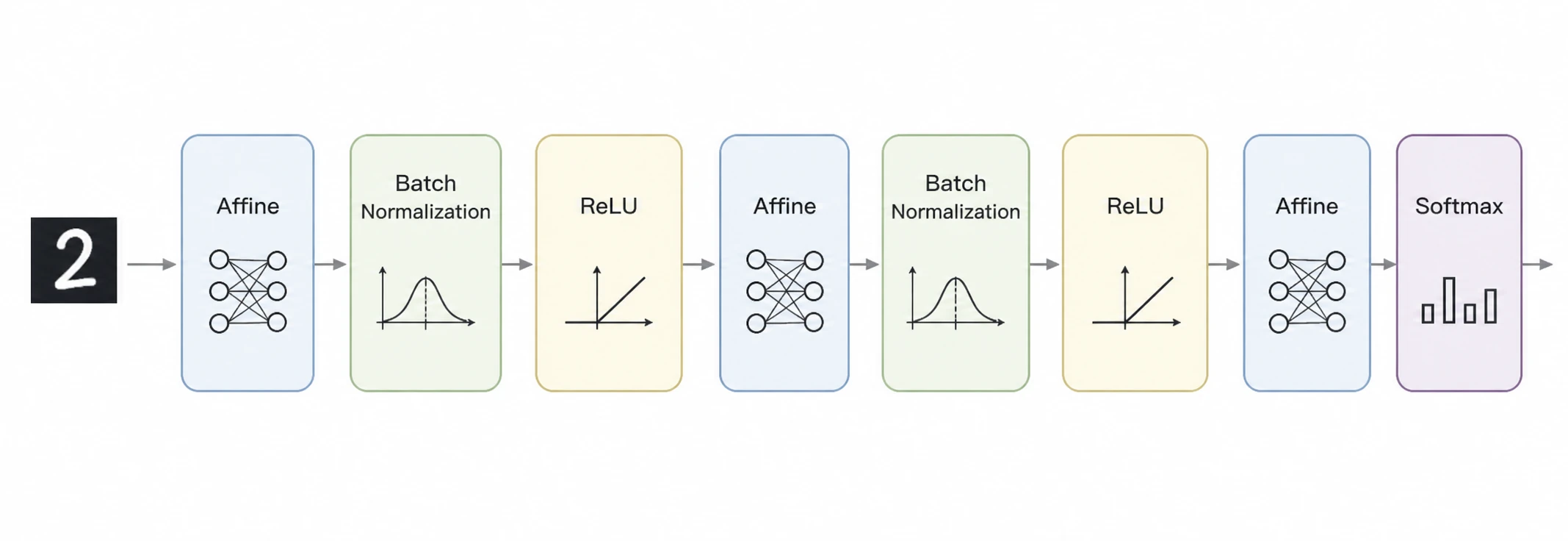
구조
배치 정규화 계층은 신경망 중간에 삽입한다.
일반적으로 Linear 또는 Convolution 계층 바로 다음, ReLU 같은 활성화 함수 바로 앞에 BatchNorm을 위치시킨다.
이렇게 배치하는 이유는 다음과 같다.
- 활성화 함수 적용 이전에 Linear/Conv 출력의 분포를 안정화하여 기울기 소실 또는 폭발 문제를 줄인다.
- ReLU 같은 비선형 활성화 함수가 균형 잡힌 분포를 가진 입력값을 받도록 한다.
- 활성화 함수의 입력값 분포가 대칭적이고 적당한 스케일을 가지면 학습이 안정적으로 진행된다.
ReLU의 경우 음수 입력은 뉴런을 죽인다. 반대로 값이 양수 쪽으로만 치우쳐 분포하면 gradient가 한쪽으로 몰리고, ReLU가 사실상 항등함수처럼 작동하여 비선형 함수의 역할이 약해질 수 있다.
결국 활성화 함수를 거치는 과정에서 기울기 소실 또는 폭발 문제가 생길 수 있으므로, 활성화 함수에 들어가기 전 분포를 적절하게 정리하는 것이 중요하다.
원리
배치 정규화는 데이터 분포가 평균 0, 분산 1이 되도록 입력을 정규화한다.
미니배치 에 개의 데이터가 있다고 하자.
먼저 미니배치 평균을 구한다.
다음으로 미니배치 분산을 구한다.
이후 입력 데이터를 평균 0, 분산 1이 되도록 정규화한다.
위 식에서 각 항의 의미는 다음과 같다.
- : 평균을 제거하여 데이터의 중심을 0으로 이동시킨다.
- : 표준편차로 나누어 분산을 1로 조정한다.
- : 분산이 0에 가까울 때 0으로 나누는 문제를 막기 위한 작은 값이다.
이 과정은 통계학에서 사용하는 표준화와 거의 동일하다.
즉, 미니배치 단위로 평균과 분산을 계산한 뒤 입력 데이터가 평균 0, 분산 1이 되도록 정규화하는 것이다.
이 처리를 활성화 함수 앞 또는 뒤에 삽입하면 데이터 분포가 덜 치우치도록 조정할 수 있다.
Scale과 Shift
배치 정규화는 단순히 정규화만 하고 끝나지 않는다.
배치 정규화 계층마다 정규화된 데이터에 고유한 확대(scale)와 이동(shift)을 수행한다.
위 식에서 는 확대, 는 이동을 의미한다.
초기에는 보통 , 에서 시작하고, 학습이 진행되며 두 값이 함께 조절된다.
이 알고리즘은 순전파에서 사용된다.
역전파
배치 정규화의 역전파에서는 손실 함수의 미분 가 주어졌을 때, 이를 기반으로 다음 값을 도출해야 한다.
- 입력값에 대한 미분:
- 스케일 파라미터에 대한 미분:
- 시프트 파라미터에 대한 미분:
아래 그래프는 배치 정규화 역전파 흐름을 나타낸 것이다.
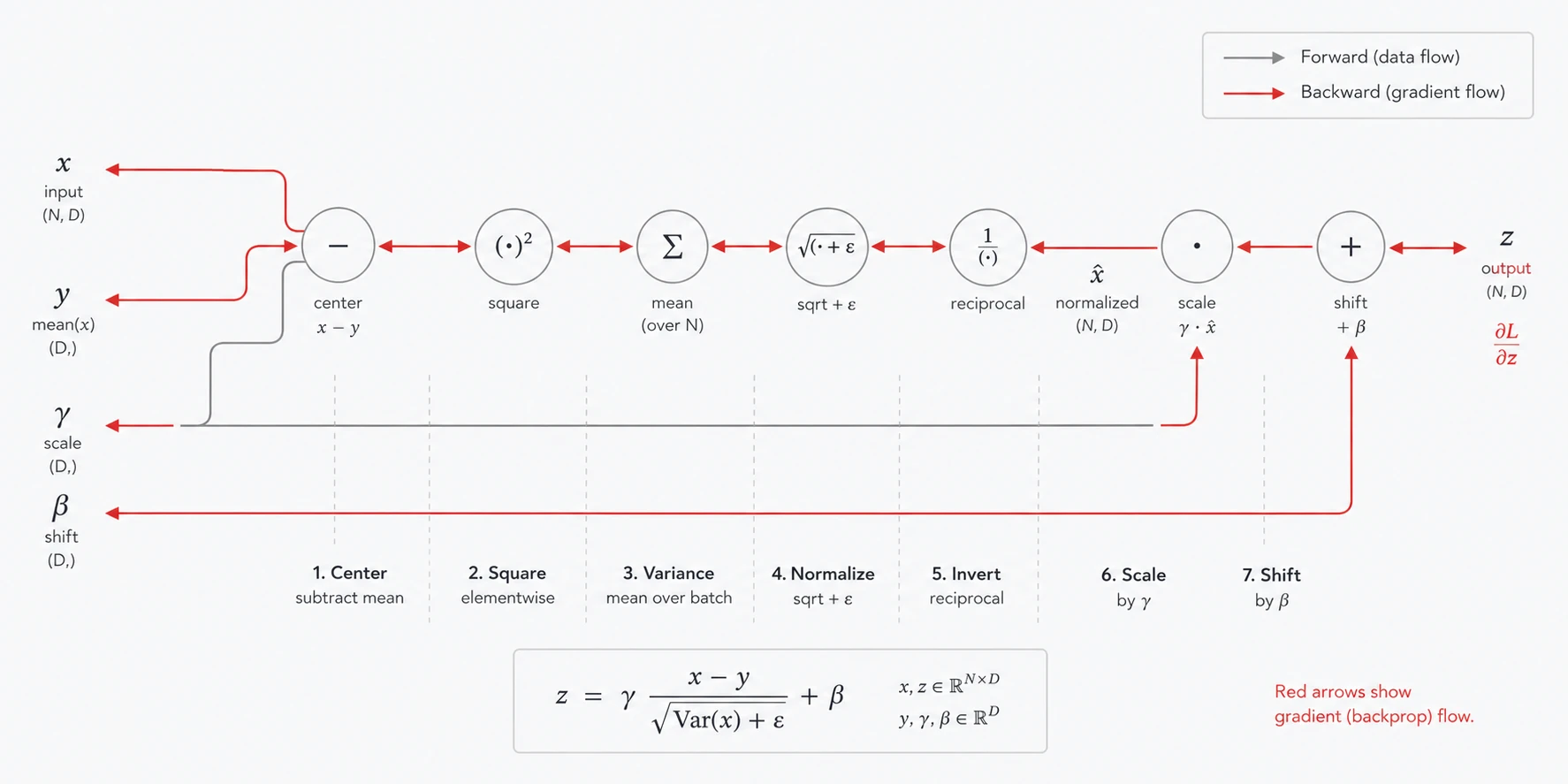
역전파 수식은 참고용으로 보면 된다.
먼저 스케일 파라미터와 시프트 파라미터의 미분은 다음과 같다.
입력에 대한 미분은 다음과 같다.
이 식은 다음 세 부분의 기울기 영향을 포함한다.
- 직접적인 gradient 영향
- 평균을 빼는 과정이 gradient에 끼치는 영향
- 분산 정규화가 gradient에 끼치는 영향
| 의미 | 식에서 해당 부분 |
|---|---|
| 직접적인 gradient 영향 | |
| 평균을 빼는 과정의 영향 | |
| 분산 정규화의 영향 |
배치 정규화의 효과
배치 정규화는 학습 속도를 높이고 학습을 안정화한다.
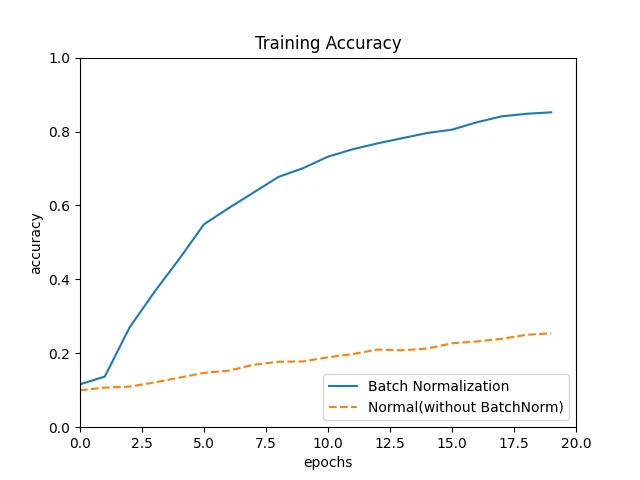
위 결과에서는 배치 정규화가 학습 속도를 높이고 있는 모습을 관찰할 수 있다.
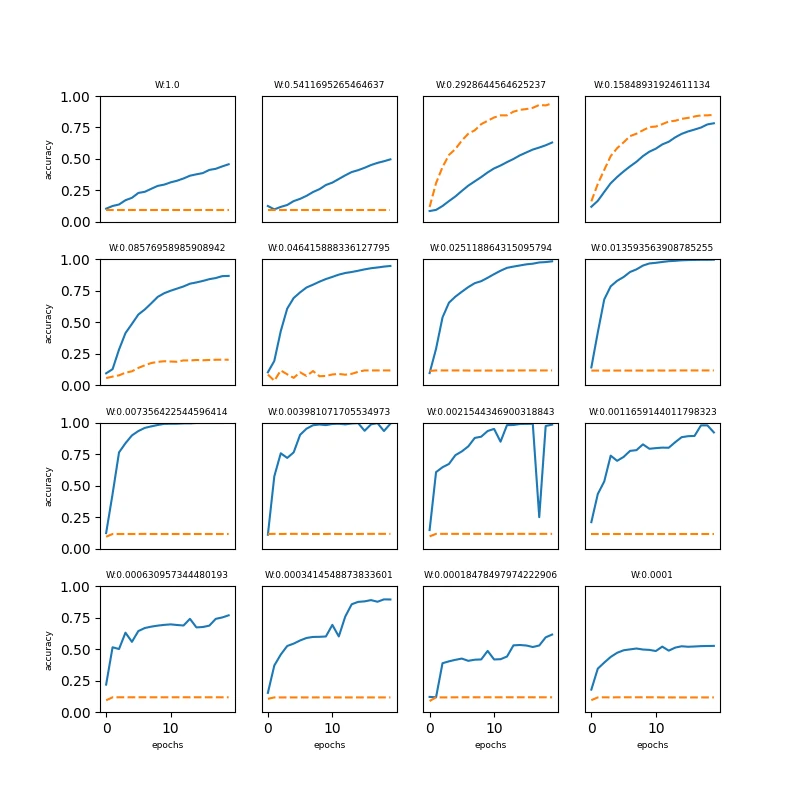
표준편차를 다르게 하여 테스트한 경우에도 대부분의 경우에서 배치 정규화를 적용한 모델의 학습 속도가 더 빠르다.
배치 정규화 구현
아래는 배치 정규화 계층 구현 예시이다.
class BatchNormalization:
"""
http://arxiv.org/abs/1502.03167
"""
def __init__(self, gamma, beta, momentum=0.9, running_mean=None, running_var=None):
self.gamma = gamma
self.beta = beta
self.momentum = momentum
self.input_shape = None # 합성곱 계층은 4차원, 완전연결 계층은 2차원
# 시험할 때 사용할 평균과 분산
self.running_mean = running_mean
self.running_var = running_var
# backward 시에 사용할 중간 데이터
self.batch_size = None
self.xc = None
self.std = None
self.dgamma = None
self.dbeta = None
def forward(self, x, train_flg=True): # 순전파
self.input_shape = x.shape
if x.ndim != 2:
N, C, H, W = x.shape
x = x.reshape(N, -1)
out = self.__forward(x, train_flg)
return out.reshape(*self.input_shape)
def __forward(self, x, train_flg): # 정규화 수행
if self.running_mean is None:
N, D = x.shape
self.running_mean = np.zeros(D)
self.running_var = np.zeros(D)
if train_flg:
mu = x.mean(axis=0) # 입력 x의 배치별 평균
xc = x - mu # 편차
var = np.mean(xc**2, axis=0) # 분산
std = np.sqrt(var + 10e-7) # 표준편차
xn = xc / std # 정규화된 입력
self.batch_size = x.shape[0]
self.xc = xc
self.xn = xn
self.std = std
self.running_mean = self.momentum * self.running_mean + (1 - self.momentum) * mu
self.running_var = self.momentum * self.running_var + (1 - self.momentum) * var
else:
xc = x - self.running_mean
xn = xc / (np.sqrt(self.running_var + 10e-7))
out = self.gamma * xn + self.beta
return out
def backward(self, dout):
if dout.ndim != 2:
N, C, H, W = dout.shape
dout = dout.reshape(N, -1)
dx = self.__backward(dout)
dx = dx.reshape(*self.input_shape)
return dx
def __backward(self, dout):
dbeta = dout.sum(axis=0)
dgamma = np.sum(self.xn * dout, axis=0)
dxn = self.gamma * dout
dxc = dxn / self.std
dstd = -np.sum((dxn * self.xc) / (self.std * self.std), axis=0)
dvar = 0.5 * dstd / self.std
dxc += (2.0 / self.batch_size) * self.xc * dvar
dmu = np.sum(dxc, axis=0)
dx = dxc - dmu / self.batch_size
self.dgamma = dgamma
self.dbeta = dbeta
return dx다층 신경망에서 BatchNorm 적용
아래는 완전 연결 다층 신경망에서 배치 정규화를 선택적으로 사용하는 구현 예시이다.
# coding: utf-8
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), '..'))
import numpy as np
from collections import OrderedDict
from common.layers import *
from common.gradient import numerical_gradient
class MultiLayerNetExtend:
"""완전 연결 다층 신경망(확장판)
가중치 감소, 드롭아웃, 배치 정규화 구현
Parameters
----------
input_size : 입력 크기(MNIST의 경우 784)
hidden_size_list : 각 은닉층의 뉴런 수를 담은 리스트(e.g. [100, 100, 100])
output_size : 출력 크기(MNIST의 경우 10)
activation : 활성화 함수 - 'relu' 혹은 'sigmoid'
weight_init_std : 가중치의 표준편차 지정(e.g. 0.01)
'relu'나 'he'로 지정하면 He 초깃값으로 설정
'sigmoid'나 'xavier'로 지정하면 Xavier 초깃값으로 설정
weight_decay_lambda : 가중치 감소(L2 법칙)의 세기
use_dropout : 드롭아웃 사용 여부
dropout_ration : 드롭아웃 비율
use_batchnorm : 배치 정규화 사용 여부
"""
def __init__(self, input_size, hidden_size_list, output_size,
activation='relu', weight_init_std='relu', weight_decay_lambda=0,
use_dropout=False, dropout_ration=0.5, use_batchnorm=False):
self.input_size = input_size
self.output_size = output_size
self.hidden_size_list = hidden_size_list
self.hidden_layer_num = len(hidden_size_list)
self.use_dropout = use_dropout
self.weight_decay_lambda = weight_decay_lambda
self.use_batchnorm = use_batchnorm
self.params = {}
# 가중치 초기화
self.__init_weight(weight_init_std)
# 계층 생성
activation_layer = {'sigmoid': Sigmoid, 'relu': Relu}
self.layers = OrderedDict()
for idx in range(1, self.hidden_layer_num + 1):
self.layers['Affine' + str(idx)] = Affine(self.params['W' + str(idx)],
self.params['b' + str(idx)])
if self.use_batchnorm:
self.params['gamma' + str(idx)] = np.ones(hidden_size_list[idx - 1])
self.params['beta' + str(idx)] = np.zeros(hidden_size_list[idx - 1])
self.layers['BatchNorm' + str(idx)] = BatchNormalization(
self.params['gamma' + str(idx)],
self.params['beta' + str(idx)]
)
self.layers['Activation_function' + str(idx)] = activation_layer[activation]()
if self.use_dropout:
self.layers['Dropout' + str(idx)] = Dropout(dropout_ration)
idx = self.hidden_layer_num + 1
self.layers['Affine' + str(idx)] = Affine(self.params['W' + str(idx)],
self.params['b' + str(idx)])
self.last_layer = SoftmaxWithLoss()
def __init_weight(self, weight_init_std):
"""가중치 초기화
Parameters
----------
weight_init_std : 가중치의 표준편차 지정(e.g. 0.01)
'relu'나 'he'로 지정하면 He 초깃값으로 설정
'sigmoid'나 'xavier'로 지정하면 Xavier 초깃값으로 설정
"""
all_size_list = [self.input_size] + self.hidden_size_list + [self.output_size]
for idx in range(1, len(all_size_list)):
scale = weight_init_std
if str(weight_init_std).lower() in ('relu', 'he'):
scale = np.sqrt(2.0 / all_size_list[idx - 1])
elif str(weight_init_std).lower() in ('sigmoid', 'xavier'):
scale = np.sqrt(1.0 / all_size_list[idx - 1])
self.params['W' + str(idx)] = scale * np.random.randn(
all_size_list[idx - 1],
all_size_list[idx]
)
self.params['b' + str(idx)] = np.zeros(all_size_list[idx])
def predict(self, x, train_flg=False):
for key, layer in self.layers.items():
if "Dropout" in key or "BatchNorm" in key:
x = layer.forward(x, train_flg)
else:
x = layer.forward(x)
return x
def loss(self, x, t, train_flg=False):
"""손실 함수를 구한다.
Parameters
----------
x : 입력 데이터
t : 정답 레이블
"""
y = self.predict(x, train_flg)
weight_decay = 0
for idx in range(1, self.hidden_layer_num + 2):
W = self.params['W' + str(idx)]
weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W**2)
return self.last_layer.forward(y, t) + weight_decay
def accuracy(self, X, T):
Y = self.predict(X, train_flg=False)
Y = np.argmax(Y, axis=1)
if T.ndim != 1:
T = np.argmax(T, axis=1)
accuracy = np.sum(Y == T) / float(X.shape[0])
return accuracy
def numerical_gradient(self, X, T):
"""기울기를 구한다(수치 미분).
Parameters
----------
x : 입력 데이터
t : 정답 레이블
Returns
-------
각 층의 기울기를 담은 사전(dictionary) 변수
grads['W1'], grads['W2'], ... 각 층의 가중치
grads['b1'], grads['b2'], ... 각 층의 편향
"""
loss_W = lambda W: self.loss(X, T, train_flg=True)
grads = {}
for idx in range(1, self.hidden_layer_num + 2):
grads['W' + str(idx)] = numerical_gradient(loss_W, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_W, self.params['b' + str(idx)])
if self.use_batchnorm and idx != self.hidden_layer_num + 1:
grads['gamma' + str(idx)] = numerical_gradient(loss_W, self.params['gamma' + str(idx)])
grads['beta' + str(idx)] = numerical_gradient(loss_W, self.params['beta' + str(idx)])
return grads
def gradient(self, x, t):
# forward
self.loss(x, t, train_flg=True)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 결과 저장
grads = {}
for idx in range(1, self.hidden_layer_num + 2):
grads['W' + str(idx)] = (
self.layers['Affine' + str(idx)].dW
+ self.weight_decay_lambda * self.params['W' + str(idx)]
)
grads['b' + str(idx)] = self.layers['Affine' + str(idx)].db
if self.use_batchnorm and idx != self.hidden_layer_num + 1:
grads['gamma' + str(idx)] = self.layers['BatchNorm' + str(idx)].dgamma
grads['beta' + str(idx)] = self.layers['BatchNorm' + str(idx)].dbeta
return grads정리
배치 정규화는 미니배치 단위로 평균과 분산을 계산하여 각 층의 입력 분포를 안정화하는 기법이다.
각 층의 입력 분포가 안정되면 학습률을 더 크게 설정하기 쉬워지고, 학습 속도와 안정성이 개선된다.
또한 배치 단위 통계량을 사용하기 때문에 약한 정규화 효과가 있어 과대적합 억제에도 도움이 된다.
핵심은 정규화 이후에도 와 를 학습하여, 네트워크가 필요한 분포를 다시 표현할 수 있도록 만든다는 점이다.