한빛미디어의 <밑바닥부터 시작하는 딥러닝 2>를 요약 정리한 글이다.
CBOW 모델을 큰 어휘 집합에 그대로 적용하면 계산량이 매우 커진다.
예를 들어 어휘 수가 100만 개라면 입력 원-핫 벡터도 100만 차원이 되고, 출력층에서도 100만 개 단어에 대한 점수를 계산해야 한다.
이 문제를 줄이기 위해 두 가지 기법을 사용한다.
- 입력 쪽에서는
Embedding계층으로 원-핫 벡터와 행렬곱을 대체한다. - 출력 쪽에서는
Negative Sampling으로 전체 softmax 계산을 일부 샘플에 대한 이진 분류 문제로 바꾼다.
전체 흐름
학습 시 흐름은 다음과 같다.
one-hot vector
→ embedding(W_in)
→ sum / average
→ h(context vector)
→ embedding dot(W_out)
→ negative sampling
→ binary cross entropy loss
→ sum(loss)
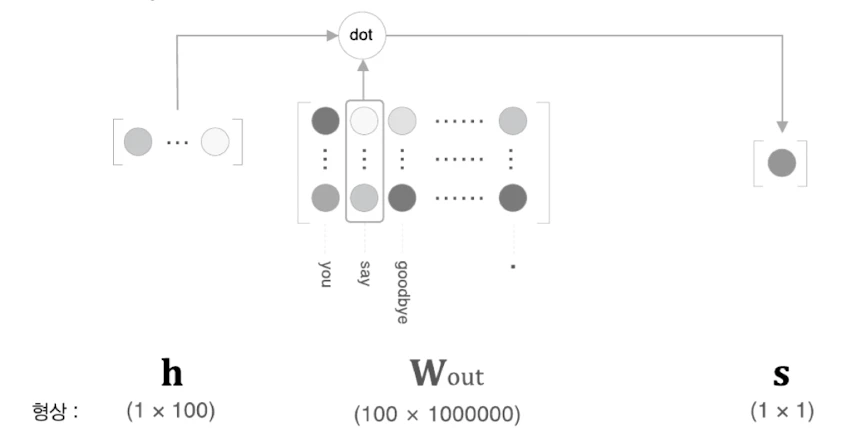
→ backward추론 시에는 문맥 벡터 와 출력 가중치 을 이용해 모든 단어의 점수를 계산한다.
여기서 의 크기가 이고, 의 크기가 이면, 결과 score는 가 된다.
각 원소 는 문맥 벡터 와 단어 의 출력 벡터 사이의 내적 점수이다.
점수가 클수록 해당 단어가 현재 문맥에 적합하다고 모델이 판단한다.
계산량 문제
CBOW에서 어휘 수를 , 은닉층 크기를 라고 하자.
어휘 수가 이고 은닉층 크기가 이면 입력층과 은닉층 사이의 가중치는 다음 크기를 가진다.
출력층 가중치는 다음 크기를 가진다.
여기서 문제가 되는 부분은 두 가지이다.
- 입력 원-핫 벡터가 너무 커서 행렬곱 계산량이 크다.
- 출력층에서 모든 단어에 대한 score와 softmax를 계산해야 해서 계산량이 크다.
Embedding 계층은 첫 번째 문제를 줄이고, Negative Sampling은 두 번째 문제를 줄인다.
Embedding 계층
Embedding 계층은 가중치 매개변수에서 단어 ID에 해당하는 벡터만 추출하는 계층이다.
원래는 단어 의 one-hot 벡터 와 입력 가중치 을 곱해 임베딩 벡터를 얻는다.
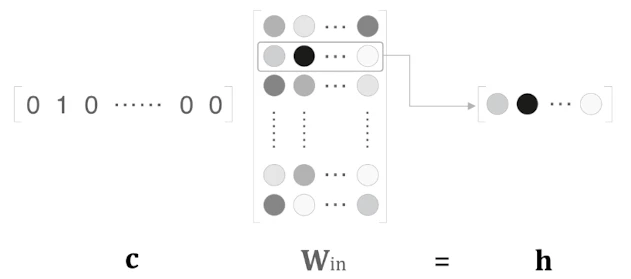
하지만 one-hot 벡터는 대부분이 0이고 특정 위치 하나만 1이다.
따라서 one-hot 벡터와 의 행렬곱은 결국 에서 특정 행 하나를 꺼내는 것과 같다.
단어 ID가 라면 결과는 다음과 같다.
즉, Embedding 계층은 불필요한 행렬곱을 하지 않고 인덱스로 필요한 벡터만 가져온다.
이렇게 얻은 단어의 밀집 벡터 표현을 단어 임베딩 또는 분산 표현이라고 한다.
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
np.add.at(dW, self.idx, dout)
return None순전파에서는 W[idx]로 필요한 행만 추출한다.
역전파에서는 입력 단어 ID 자체에 대한 gradient는 필요하지 않으므로 None을 반환한다.
대신 추출했던 행에 해당하는 위치로 gradient를 되돌려 넣는다.
중복 Index 문제
Embedding 계층의 역전파에서는 같은 index가 여러 번 등장할 수 있다.
예를 들어 index가 다음과 같다고 하자.
[0, 2, 0, 4]그러면 , , , 가 추출된다.
여기서 는 두 번 사용되었다.
따라서 역전파 시에도 에 대한 gradient가 두 번 발생한다.
이를 각각 , 라고 하면, 최종 gradient는 다음처럼 더해져야 한다.
그래서 단순히 값을 대입하면 안 된다.
dW[idx] = dout이렇게 하면 같은 index가 반복될 때 뒤의 gradient가 앞의 gradient를 덮어쓴다.
따라서 np.add.at을 사용해 같은 index에 대한 gradient를 누적한다.
np.add.at(dW, self.idx, dout)Gradient를 누적하는 이유
기울기는 손실 을 어떤 파라미터로 편미분한 값이다.
그런데 손실 이 여러 항의 합으로 구성되어 있다면, 미분의 선형성 때문에 각 항의 기여가 더해진다.
예를 들어 손실이 다음과 같다고 하자.
그러면 특정 파라미터 에 대한 gradient는 다음과 같다.
즉, 같은 임베딩 행이 여러 위치에서 사용되었다면 각 위치에서 발생한 gradient를 모두 합산해야 한다.
Embedding 계층에서 gradient를 누적하는 이유도 여기에 있다.
Softmax의 문제
출력층에서 일반 softmax를 사용하면 모든 단어에 대한 score를 계산하고 정규화해야 한다.
여기서 는 어휘 수이다.
어휘 수가 커질수록 softmax 계산량도 에 비례해 커진다.
word2vec에서는 이 문제를 완화하기 위해 Negative Sampling을 사용한다.
Negative Sampling의 직관
Negative Sampling의 핵심은 다중 분류 문제를 여러 개의 이진 분류 문제로 바꾸는 것이다.
원래 문제는 다음과 같다.
현재 문맥에서 정답 단어는 무엇인가?Negative Sampling에서는 이를 다음 질문으로 바꾼다.
이 단어는 현재 문맥에 맞는 단어인가?정답 단어는 positive sample로 두고, 무작위로 뽑은 오답 단어들은 negative sample로 둔다.
- Positive sample: 현재 문맥에 맞는 단어이므로 label은 1이다.
- Negative sample: 현재 문맥에 맞지 않는 단어이므로 label은 0이다.
문맥 벡터 와 단어 벡터 의 내적이 크면 모델은 True에 가깝게 판단하고, 내적이 작으면 False에 가깝게 판단한다.
정답 샘플의 경우에는 가 1에 가까워져야 한다.
반대로 부정 샘플의 경우에는 가 0에 가까워져야 한다.
Sigmoid와 Binary Cross Entropy
이진 분류에서는 점수를 확률처럼 해석하기 위해 sigmoid 함수를 사용한다.
sigmoid 출력 를 얻은 뒤, binary cross entropy로 손실을 계산한다.
여기서 는 정답 레이블이다.
정답이 1이면 손실은 다음과 같다.
이 경우 가 1에 가까울수록 손실은 0에 가까워지고, 가 0에 가까울수록 손실은 커진다.
정답이 0이면 손실은 다음과 같다.
이 경우 가 0에 가까울수록 손실은 0에 가까워지고, 가 1에 가까울수록 손실은 커진다.
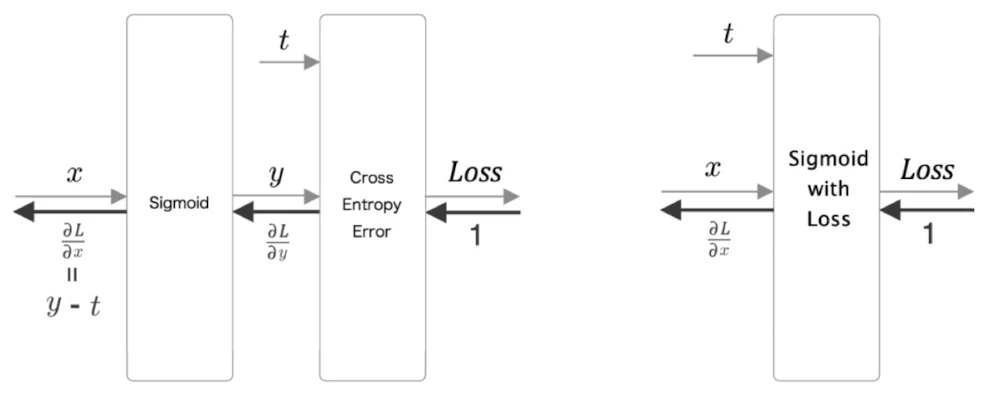
sigmoid와 binary cross entropy를 함께 사용하면 역전파 값은 다음처럼 정리된다.
이는 softmax와 cross entropy를 함께 사용할 때 gradient가 로 정리되는 것과 비슷하다.
그래서 구현에서는 SigmoidWithLoss 계층으로 묶어서 사용한다.
다중 분류에서 이진 분류로
기존 CBOW 구조에서는 문맥 벡터 를 만든 뒤 모든 단어에 대한 score를 계산하고 softmax를 적용한다.
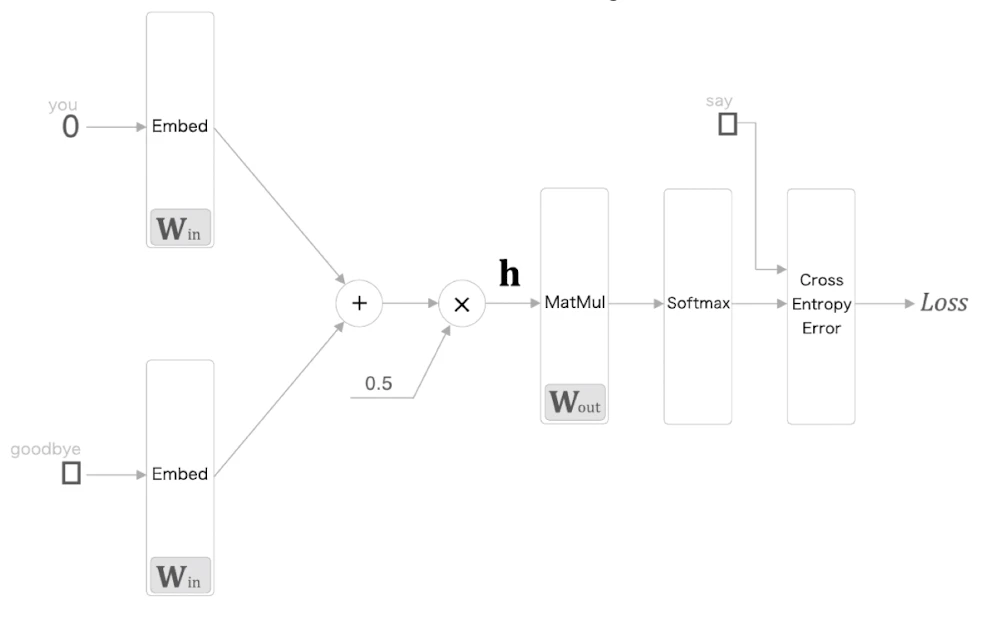
Negative Sampling에서는 모든 단어를 대상으로 softmax를 계산하지 않는다.
대신 정답 단어와 몇 개의 부정 샘플에 대해서만 이진 분류 손실을 계산한다.
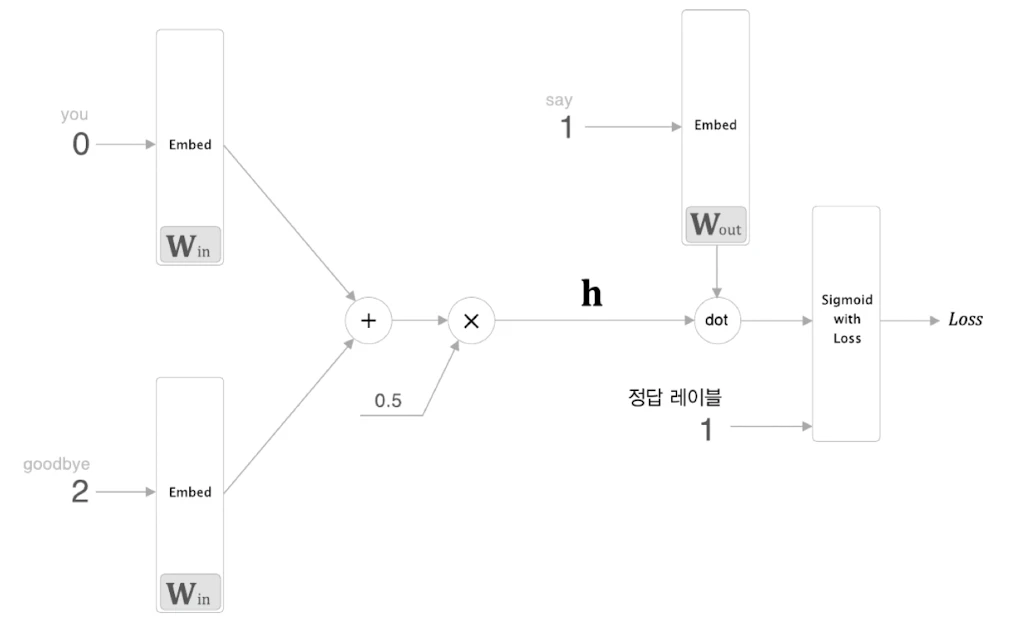
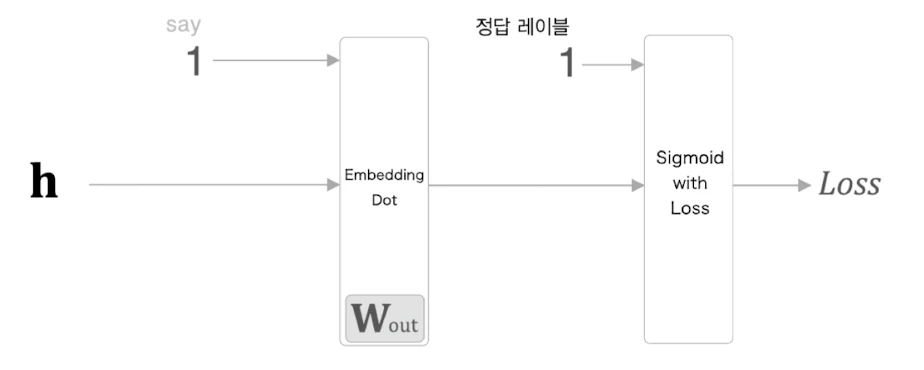
이때 문맥 벡터 와 출력 가중치의 특정 단어 벡터를 내적하는 계층을 EmbeddingDot 계층이라고 한다.
class EmbeddingDot:
def __init__(self, W):
self.embed = Embedding(W)
self.params = self.embed.params
self.grads = self.embed.grads
self.cache = None
def forward(self, h, idx):
target_W = self.embed.forward(idx)
out = np.sum(target_W * h, axis=1)
self.cache = (h, target_W)
return out
def backward(self, dout):
h, target_W = self.cache
dout = dout.reshape(dout.shape[0], 1)
dtarget_W = dout * h
self.embed.backward(dtarget_W)
dh = dout * target_W
return dhEmbeddingDot 계층의 순전파는 다음 내적을 계산한다.
역전파는 곱셈 노드와 같은 원리이다.
상류 gradient가 dout이라면,
이다.
즉, 문맥 벡터 와 타깃 단어 벡터 가 서로의 gradient 계산에 사용된다.
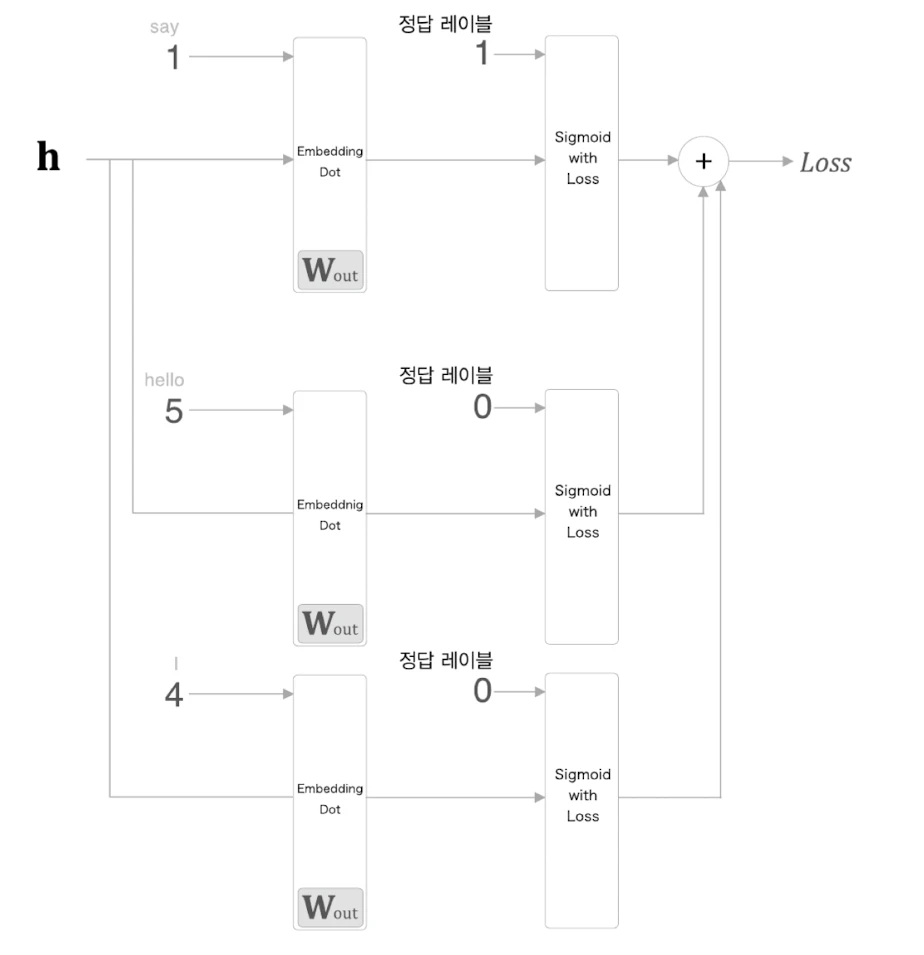
Negative Sampling 손실
Negative Sampling은 positive sample 하나와 negative sample 여러 개에 대해 손실을 계산한 뒤 모두 더한다.
Positive sample에는 label 1을 주고, negative sample에는 label 0을 준다.
class NegativeSamplingLoss:
def __init__(self, W, corpus, power=0.75, sample_size=5):
self.sample_size = sample_size
self.sampler = UnigramSampler(corpus, power, sample_size)
self.loss_layers = [SigmoidWithLoss() for _ in range(sample_size + 1)]
self.embed_dot_layers = [EmbeddingDot(W) for _ in range(sample_size + 1)]
self.params, self.grads = [], []
for layer in self.embed_dot_layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, h, target):
batch_size = target.shape[0]
negative_sample = self.sampler.get_negative_sample(target)
score = self.embed_dot_layers[0].forward(h, target)
correct_label = np.ones(batch_size, dtype=np.int32)
loss = self.loss_layers[0].forward(score, correct_label)
negative_label = np.zeros(batch_size, dtype=np.int32)
for i in range(self.sample_size):
negative_target = negative_sample[:, i]
score = self.embed_dot_layers[1 + i].forward(h, negative_target)
loss += self.loss_layers[1 + i].forward(score, negative_label)
return loss
def backward(self, dout=1):
dh = 0
for loss_layer, embed_dot_layer in zip(self.loss_layers, self.embed_dot_layers):
dscore = loss_layer.backward(dout)
dh += embed_dot_layer.backward(dscore)
return dh여기서 loss_layers와 embed_dot_layers는 sample_size + 1개 생성된다.
하나는 positive sample용이고, 나머지 sample_size개는 negative sample용이다.
역전파에서 dh +=를 사용하는 이유는 문맥 벡터 가 positive sample과 여러 negative sample의 손실에 모두 영향을 주었기 때문이다.
따라서 각 손실에서 발생한 를 모두 합산해야 최종적으로 에 대한 gradient가 된다.
이것도 미분의 선형성에 따른 gradient 누적이다.
Negative Sample을 뽑는 방법
부정 샘플은 말뭉치의 단어 출현 빈도를 기준으로 뽑는다.
자주 등장하는 단어는 샘플링될 확률이 높고, 드물게 등장하는 단어는 샘플링될 확률이 낮다.
words = ['you', 'say', 'goodbye', 'I', 'hello', '.']
p = [0.5, 0.1, 0.05, 0.2, 0.05, 0.1]
np.random.choice(words, p=p)word2vec에서는 단어 확률분포를 그대로 사용하지 않고, 각 확률에 를 제곱한 뒤 다시 정규화하는 방식을 사용한다.
이렇게 하면 출현 확률이 매우 낮은 단어에도 조금 더 기회가 생긴다.
제곱은 큰 확률은 상대적으로 낮추고 작은 확률은 상대적으로 높이는 효과를 만든다.
CBOW와 Negative Sampling
Embedding과 Negative Sampling을 적용한 CBOW의 학습 흐름은 다음과 같다.
context word ids
→ Embedding(W_in)
→ average
→ h
→ NegativeSamplingLoss(W_out)
→ lossclass CBOW:
def __init__(self, vocab_size, hidden_size, window_size, corpus):
V, H = vocab_size, hidden_size
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(V, H).astype('f')
self.in_layers = []
for i in range(2 * window_size):
layer = Embedding(W_in)
self.in_layers.append(layer)
self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size=5)
layers = self.in_layers + [self.ns_loss]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
self.word_vecs = W_in
def forward(self, contexts, target):
h = 0
for i, layer in enumerate(self.in_layers):
h += layer.forward(contexts[:, i])
h *= 1 / len(self.in_layers)
loss = self.ns_loss.forward(h, target)
return loss
def backward(self, dout=1):
dout = self.ns_loss.backward(dout)
dout *= 1 / len(self.in_layers)
for layer in self.in_layers:
layer.backward(dout)
return None여기서 는 문맥 단어 임베딩들의 평균이다.
문맥 단어 벡터가 개라면,
따라서 역전파에서는 로 들어온 gradient를 각 문맥 단어 벡터에 나누어 전달해야 한다.
손실을 로 미분한 값을 라고 하면, 각 문맥 벡터 에 대한 gradient는 다음과 같다.
그래서 코드에서 다음 처리가 들어간다.
dout *= 1 / len(self.in_layers)즉, 평균을 만들 때 를 곱했으므로 역전파에서도 각 입력 임베딩으로 만큼 나누어 gradient가 전달된다.
정리
Embedding 계층은 one-hot 벡터와 거대한 행렬곱을 직접 계산하지 않고, 단어 ID를 이용해 임베딩 행을 바로 추출한다.
Negative Sampling은 모든 단어에 대해 softmax를 계산하지 않고, positive sample과 일부 negative sample에 대해서만 이진 분류 손실을 계산한다.
이 두 기법을 사용하면 어휘 수가 큰 상황에서도 CBOW와 word2vec을 훨씬 효율적으로 학습할 수 있다.