한빛미디어의 <밑바닥부터 시작하는 딥러닝 2>를 요약 정리한 글이다.
CBOW(Continuous Bag-of-Words)는 문맥(context) 단어들로부터 중앙(target) 단어를 예측하는 신경망 기반 언어 모델이다.
주변 단어들을 입력으로 사용하고, 그 주변 단어들 사이에 위치한 중심 단어를 맞히도록 학습한다.
CBOW의 기본 구조
윈도우 크기를 이라고 하면, 시점 의 중앙 단어 를 예측하기 위해 주변 문맥 단어를 사용한다.
입력 문맥은 다음과 같다.
출력은 중앙 단어이다.
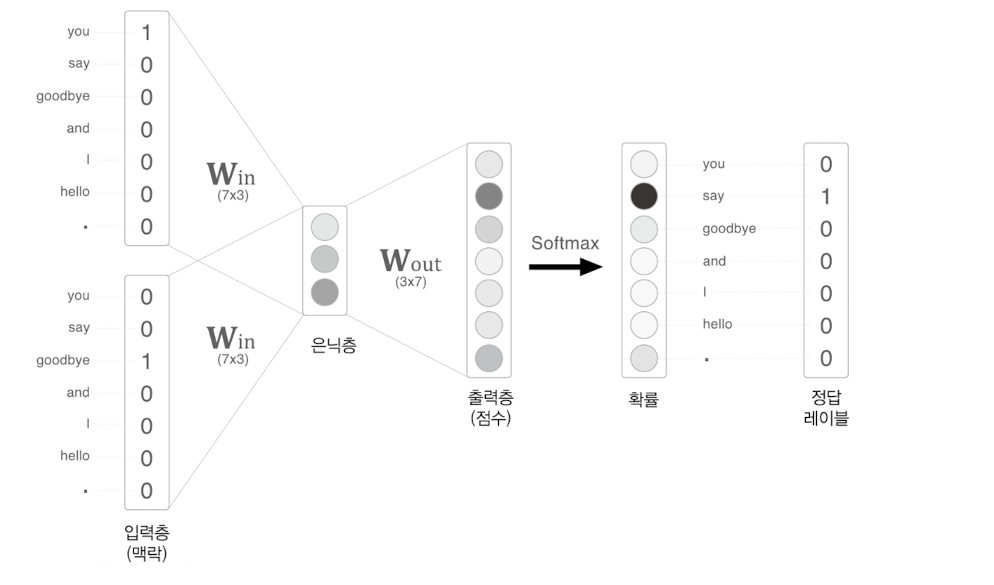
예를 들어 You ___ hello and ... 같은 문장이 있을 때, 주변 단어인 You, hello, and 등을 이용해 빈칸에 들어갈 중심 단어를 예측하는 방식이다.
임베딩 벡터
CBOW에서 각 단어 는 임베딩 벡터로 표현된다.
원-핫 벡터와 입력 가중치 행렬 의 내적을 계산하거나, 단어 인덱스를 이용해 의 특정 행을 추출하면 해당 단어의 임베딩 벡터를 얻을 수 있다.
즉, 은 단어 임베딩 테이블처럼 동작한다.
문맥 벡터 는 문맥 단어 벡터들의 평균으로 계산된다.
윈도우 크기가 이면 문맥 단어 수는 보통 개이다.
CBOW에서 이 문맥 벡터 는 은닉층(hidden layer)에 해당한다.
Negative Log Likelihood
CBOW는 최대 우도 추정(MLE, Maximum Likelihood Estimation)에 기반하여 학습할 수 있다.
윈도우 크기가 1인 경우, 시점 에서 문맥 단어 , 을 보고 중앙 단어 를 예측한다고 하자.
이때 모델이 최대화하려는 확률은 다음과 같다.
이를 손실 함수로 만들기 위해 음의 로그를 취하면 NLL(Negative Log Likelihood)이 된다.
말뭉치 전체로 확장하면 다음과 같다.
여기서 는 말뭉치 전체의 길이이다.
는 신경망의 출력에 softmax를 적용한 추론값이다.
즉, 주변 문맥을 반영한 뒤 각 단어가 중앙 단어일 확률을 계산한 값이다.
정답 단어 에 해당하는 위치의 확률을 꺼내 로그를 취하고, 음수를 붙이면 해당 위치의 손실이 된다.
전체 말뭉치 기준에서는 를 곱해 평균 손실을 구한다.
실제 구현에서는 보통 배치 학습을 사용하므로, 배치 손실의 평균을 이용한다.
배치 크기를 라고 하면 손실합에 를 곱해 배치 평균 손실을 계산한다.
이는 전체 말뭉치 평균 손실에 대한 근사로 볼 수 있다.
Cross Entropy Error와의 관계
CBOW에서 softmax 출력과 정답 원-핫 벡터를 사용하면 Cross Entropy Error(CE)를 사용할 수 있다.
정답이 원-핫 벡터일 때 CE는 정답 클래스 위치의 확률만 남긴 뒤 로그를 취한다.
따라서 CBOW의 NLL과 CE는 구현 관점에서 거의 같은 형태로 사용된다.
즉, softmax로 나온 단어 확률 분포에서 정답 단어 확률을 꺼내고, 그 값에 를 적용하는 구조이다.
Skip-Gram
skip-gram은 CBOW에서 다루는 문맥과 타깃을 반대로 뒤집은 모델이다.
CBOW는 주변 문맥 단어들을 보고 중앙 단어를 예측한다.
반대로 skip-gram은 중앙 단어를 보고 주변 문맥 단어들을 예측한다.
예를 들어 다음과 같이 이해할 수 있다.
CBOW: You ___ hello and ...
skip-gram: ___ say ___ and ...skip-gram에서는 중심 단어가 주어졌을 때 여러 개의 문맥 단어를 예측해야 한다.
따라서 출력층에서는 문맥 수만큼의 예측이 필요하다.
Skip-Gram의 확률 분해
중앙 단어 가 주어졌을 때, 양쪽 문맥 단어 과 이 동시에 등장할 확률은 다음과 같다.
skip-gram 모델은 문맥 단어들 사이에 관련이 없다고 가정한다.
즉, 중심 단어가 주어졌을 때 문맥 단어들은 조건부 독립이라고 가정한다.
따라서 확률을 다음과 같이 분해할 수 있다.
이 확률을 손실 함수에 적용하면 다음과 같다.
조건부 독립 가정에 의해 다음과 같이 전개된다.
로그의 곱셈 성질을 이용하면 다음과 같다.
즉, skip-gram의 손실 함수는 각 문맥 단어에 대해 구한 손실의 총합이다.
Skip-Gram의 말뭉치 전체 손실
윈도우 크기가 일 때, 말뭉치 전체에 대한 skip-gram 손실은 다음과 같이 쓸 수 있다.
위 식은 중심 단어 를 기준으로, 주변 문맥 단어 를 각각 예측하는 손실을 모두 더한 것이다.
CBOW와 Skip-Gram의 차이
말뭉치가 커질수록 저빈도 단어나 유추 문제의 성능 측면에서 skip-gram 모델이 더 뛰어난 경향이 있다.
단어 분산 표현의 정밀도 측면에서도 skip-gram의 결과가 더 좋은 경우가 많다.
skip-gram은 중심 단어 1개에 대해 여러 문맥 단어를 개별적으로 예측한다.
따라서 중심 단어 임베딩이 비교적 세밀하게 조정된다.
특히 희귀 단어가 중심 단어가 되면, 그 희귀 단어를 기준으로 여러 문맥 단어에 대한 손실을 계산한다.
이 과정에서 희귀 단어의 중심 단어 벡터는 문맥 단어와의 관계를 반복적으로 학습하게 된다.
즉, 희귀 단어에 대해서도 gradient가 업데이트될 기회를 더 많이 얻을 수 있다.
반면 CBOW는 여러 문맥 단어의 평균을 사용해 중심 단어를 예측한다.
여러 문맥 단어의 정보가 평균에 의해 섞이기 때문에 희귀 단어의 정보가 희석될 수 있다.
따라서 희귀 단어의 임베딩은 skip-gram보다 덜 정밀하게 학습될 수 있다.
통계 기반 기법과 추론 기반 기법
word2vec은 추론 기반 기법의 대표적인 예이다.
통계 기반 기법은 전체 말뭉치의 통계를 이용한다.
예를 들어 동시발생 행렬을 만들고, SVD를 한 번 수행하여 단어의 분산 표현을 얻는다.
반면 추론 기반 기법은 말뭉치를 배치 단위로 나누고, 여러 번 학습하면서 가중치를 업데이트한다.
어휘가 바뀌는 경우
어휘 자체가 바뀌는 경우, 통계 기반 기법은 동시발생 행렬을 새로 계산하고 SVD를 다시 수행해야 한다.
반면 추론 기반 기법은 새로 학습을 수행하여 가중치 를 업데이트할 수 있다.
이 방식은 기존 학습 데이터의 손실을 최소화하면서 분산 표현을 갱신하는 방향으로 이해할 수 있다.
분산 표현의 성격
통계 기반 기법은 주로 단어의 유사성을 인코딩한다.
SVD 기반 분산 표현은 전체 동시발생 통계를 압축하여 단어 사이의 유사성을 반영한다.
반면 추론 기반 기법은 단어 유사성뿐 아니라, 단어 사이의 패턴도 학습한다.
예를 들어 word2vec은 주변 단어를 예측하거나 중심 단어를 예측하는 과정에서 단어의 사용 패턴을 함께 반영한다.
GloVe
GloVe는 통계 기반 기법과 추론 기반 기법의 성격을 일부 결합한 방법으로 볼 수 있다.
말뭉치 전체의 통계 정보를 손실 함수에 도입하여 단어 벡터를 학습한다.
즉, 전체 동시발생 통계를 활용하면서도 최적화 기반으로 단어 벡터를 학습하는 접근이다.
요약
CBOW는 주변 문맥 단어를 이용해 중심 단어를 예측하는 모델이다.
문맥 단어들의 임베딩 평균이 은닉층 역할을 하며, softmax 출력에서 정답 단어의 확률을 높이는 방향으로 학습한다.
skip-gram은 중심 단어를 이용해 주변 문맥 단어를 예측하는 모델이다.
CBOW는 학습이 비교적 빠르고, skip-gram은 희귀 단어나 유추 문제에서 더 좋은 성능을 보이는 경향이 있다.
통계 기반 기법은 전체 통계로부터 분산 표현을 얻고, 추론 기반 기법은 신경망 학습을 통해 분산 표현을 얻는다.