Overview
L1, L2 distance 에 대해 이해하고, k-Nearest Neighbors(kNN) 분류기를 직접 구현하고,
학습 데이터에 대해 성능을 측정하고, Cross-Validation (k-folds) 를 이용해 최적의 하이퍼파라미터 k를 찾기
핵심 아이디어
k-Nearest Neighbors(kNN)는 테스트 샘플과 훈련 샘플 간의 거리를 계산하여 가장 가까운 k개의 이웃을 찾고, 다수결을 통해 클래스를 예측하는 분류 알고리즘이다.
- 학습 과정이 거의 없음 (Lazy Learning)
- 가장 가까운 k개의 데이터로 분류
- 거리 척도로 주로 Euclidean Distance(L2 distance) 사용
거리 계산:
구현
two-loops -> one-loops -> no-loops(vectorization)
-
two-loops: 이중 반복문을 이용해
test[i]와train[j]간의 pixel distance 를 계산한다.
시간 복잡도: -
one-loops: 단일 반복문과 numpy의 broadcasting 을 이용해
train과test[i]간의 차이를 계산한다.
train.shape = (num_train, D)
test[i].shape = (D, )에서 numpy의 오른쪽 비교로 브로드캐스팅이 가능(D = D ->test[i].shape = (1, D))
따라서test[i]가 행 방향(axis=0) 으로 브로드캐스팅 된다. -
no-loops(vectorization): 행렬 곱셈을 이용하여 거리를 계산한다.
L2 distance 제곱을 전개하여 반복이 필요한 요소를 행렬곱으로 처리한다.각 쌍에 대해 반복 처리가 필요한 부분을 두 벡터(행렬)의 곱셈으로 내적을 한번에 계산한다.
# X.shape = (num_test, D) # X_train.shape = (num_train, D) # temp.shape = (num_test, num_train) temp = X @ X_train.T # 열 방향으로 제곱합 a_square = np.sum(X ** 2, axis=1).reshape(-1, 1) b_square = np.sum(self.X_train ** 2, axis=1) dists = np.sqrt(np.maximum(a_square + b_square - 2 * temp, 0))여기서 reshape 는
axis=1방향으로 합친 테스트 데이터X.shape = (num_test, )를 열벡터(num_test, 1)로 만듬으로써,
a_square + b_square - 2 * temp브로드캐스팅이 될 수 있게 한다.
(num_test, 1) vs (num_train, )비교 시, numpy는(num_train, )왼쪽에 1을 추가하여 비교한다.
(num_test, 1) vs (1, num_train)
-> 오른쪽부터 비교 시 train 방향으로 브로드캐스팅, test 방향으로 브로드캐스팅 =>dists.shape = (num_test, num_train)
cross-validation
k-folds 를 이용한 교차 검증으로 최적의 하이퍼파라미터 k를 결정한다.
핵심은 X_train, y_train 의 n개의 폴드로 나누고, 각 k후보에 대해서 각 folds[i]를 테스트 데이터로, 나머지는 훈련 데이터로 사용한다.
k-fold 교차 검증을 사용하는 이유는 하나의 Train/Validation 분할에만 의존하면 우연히 선택된 데이터에 의해 성능 평가가 왜곡될 수 있기 때문이다.
데이터를 n개의 fold로 나누고, 각 fold를 한 번씩 Validation 데이터로 사용하면 모든 데이터가 정확히 한 번은 Validation 데이터로 사용되고, 나머지 n-1번은 Training 데이터로 사용된다.
따라서 특정 분할에 대한 편향을 줄일 수 있으며, 각 하이퍼파라미터 k에 대해 얻은 여러 Validation 성능의 평균을 사용함으로써 일반화 성능을 더 안정적으로 추정할 수 있다.
k-fold 교차 검증은 제한된 데이터를 보다 효율적으로 활용하면서 과적합된 하이퍼파라미터 선택을 방지하기 위해 사용된다.
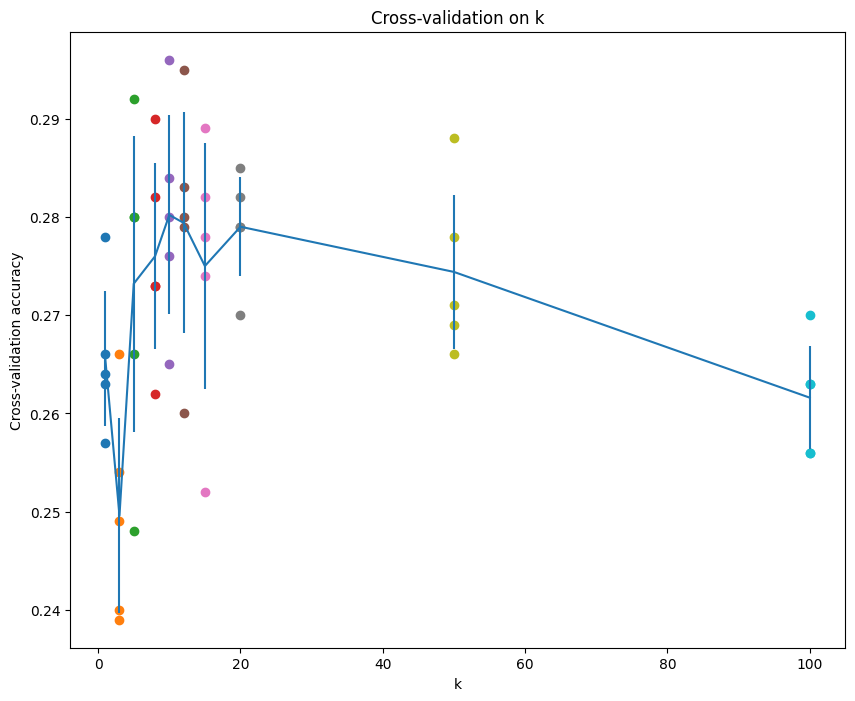
num_folds = 5, k_choices = k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100] 에서 k = 8 일때 정확도가 가장 높으면서 분산이 낮았고, 따라서 best_k = 8 로 테스트를 진행했다.
k = 8 일때, 다음 결과를 얻었다.
Got 273 / 500 correct => accuracy: 0.546000
추가 개념들
-
dists 행렬을 시각화 했을때 특정 행이 밝게 보이는 것은 각 테스트 이미지 i가 대부분의 훈련 이미지와 픽셀 수준에서 큰 차이를 보이기 때문이다. 열의 경우 반대이다.
-
L1 distance를 사용하는 경우에서
이미지 전체의 픽셀 평균 와 pixel-wise mean 가 있을때, 일반적인 편차(deviation) 와 pixel-wise deviation 는 유사하게 정의된다.
이때, 각 픽셀값 에서 어떤 연산을 가했을 때, L1 distance를 사용하는 kNN의 성능에 영향을 주지 않는 연산들은 다음과 같다.- 를 적용 하는 경우, 모든 요소가 동일하게 만큼 이동하기 때문에 L1을 사용하는 kNN의 성능에 영향을 주지 않는다.
- 를 적용 하는 경우, 모든 픽셀이 동일한 pixel-wise mean 만큼 이동하기 때문에 거리 순서에 영향을 주지 않는다.
- 이후 를 적용 하는 경우, 모든 거리값이 동일한 가중치가 붙으므로, 거리 순서를 보존한다.
포인트는 거리 순서 보존으로, 각 픽셀 간의 거리 순서가 바뀔만한 연산은 kNN의 성능에 영향을 준다.
예시로, 후 를 곱하면 각 픽셀 차이마다 이라는 가중치가 붙으므로, 변동성이 큰 픽셀은 중요도가 감소하고, 변동성이 작은 픽셀은 중요도가 높아진다.
따라서 아래의 경우 이미지 간 거리 순서를 보존하지 않는다.즉, 각 축(pixel)에 서로 다른 가중치 를 주기 때문에 상대거리가 변한다.
헷갈렷던 포인트
-
training error 에서 1-NN은 항상 0이다. 왜냐면 각 훈련 포인트의 최근접 이웃은 항상 자기 자신이기 때문이다.
k가 낮으면 표현력이 높아질 수 있지만 훈련 데이터에 대한 overfitting이 발생하고, k가 높으면 decision boundary 완만해지고 모델의 분산은 감소하지만 편향이 증가하여 underfitting이 발생할 수 있다. -
훈련 데이터 세트가 커질수록, 분류 시간은 증가한다. 왜냐면 kNN은 테스트 시점에 모든 training points 에 대한 distances 를 계산하기 때문이다.