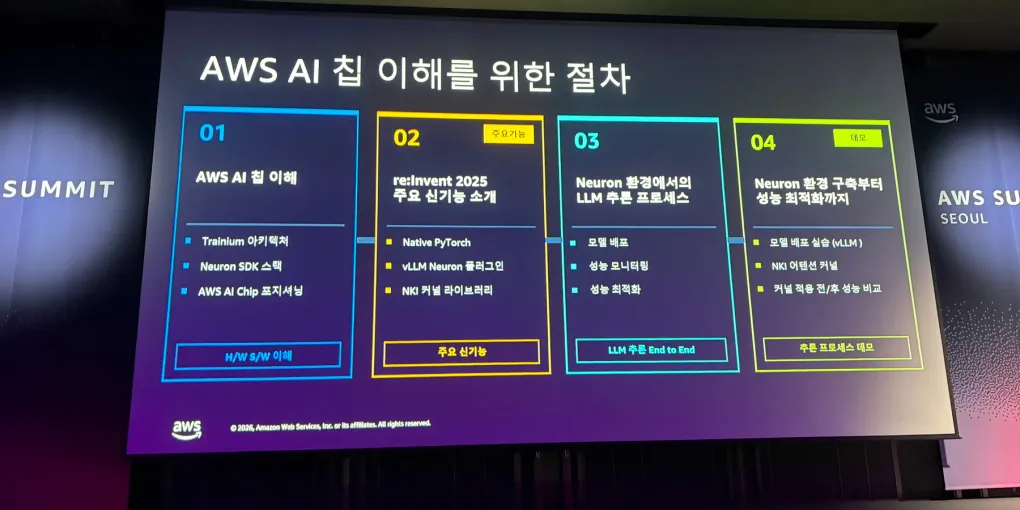
AWS Summit 2026의 마지막 세션
AWS Summit 2026에서 마지막으로 들은 세션은 AWS-Trainium 기반 LLM(Large Language Model, 대규모 언어 모델) 추론 A to Z: Neuron 환경 이해부터 성능 최적화까지였다.
하루 끝에 듣는 세션이라 집중력이 많이 떨어질 줄 알았는데, 의외로 가장 기억에 남았다. 단순히 “Trainium이 빠르다” 정도의 소개가 아니라, 실제로 LLM 추론을 Trainium 환경에서 돌리려면 어떤 것들을 봐야 하는지 전체 흐름을 잡아주는 세션이었다.
왜 AWS AI Chip인가
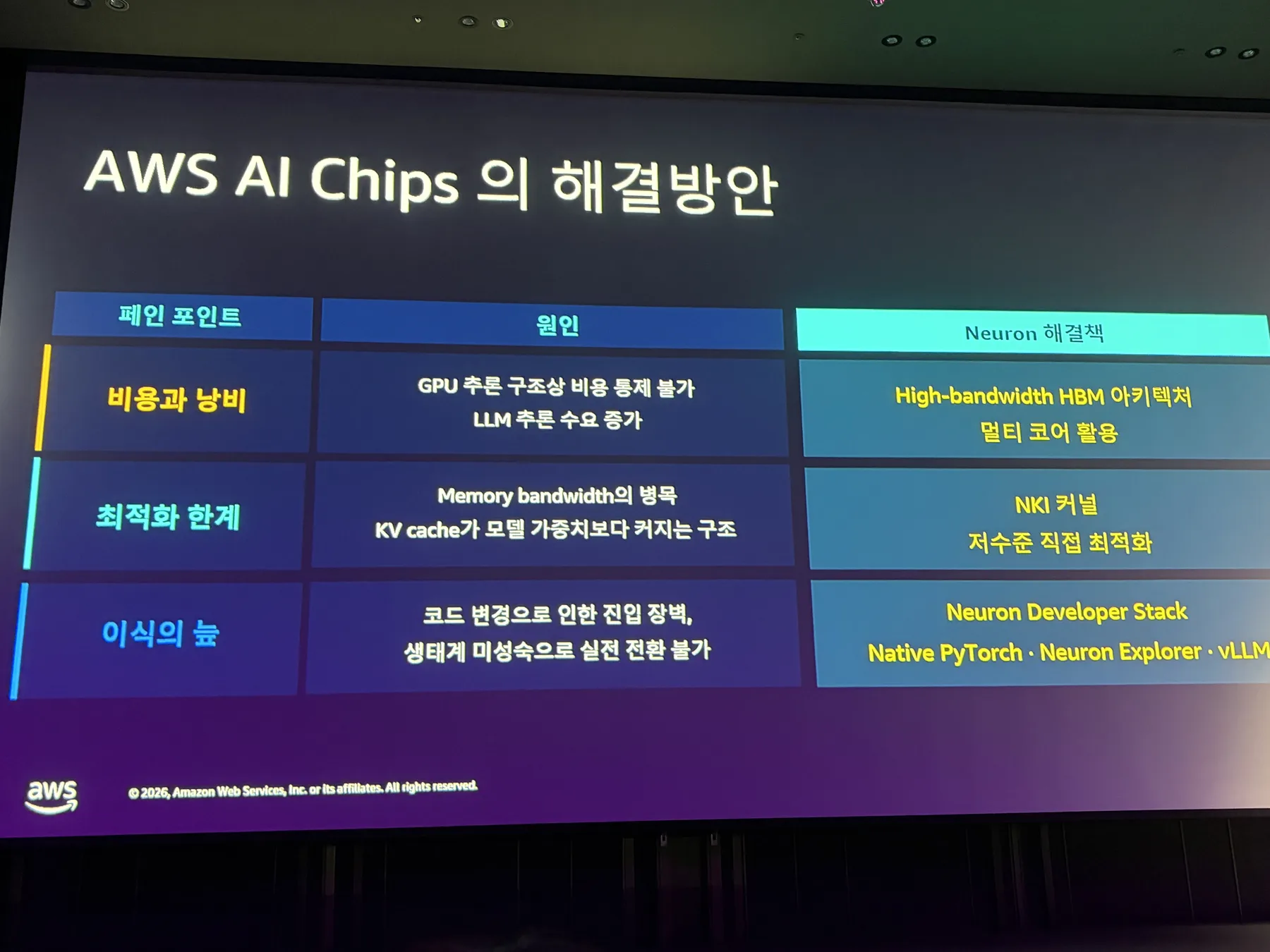
세션 초반에는 AWS AI Chip이 풀고자 하는 문제가 정리되었다.
LLM 추론 수요가 계속 늘어나면서 GPU 기반 추론 구조에서는 비용 통제가 어려워지고, memory bandwidth가 병목이 되기 쉽다. 특히 KV(Key-Value, 키-값) cache가 모델 가중치보다 더 커질 수 있는 구조라는 설명이 기억에 남았다.
즉 LLM 추론 최적화는 단순히 연산량만 보는 문제가 아니다. 모델을 올릴 수 있는지, KV cache를 얼마나 효율적으로 관리하는지, memory bandwidth를 얼마나 잘 활용하는지까지 같이 봐야 한다.
세션에서는 Claude도 AWS 데이터센터에서 Trainium, Inferentia 계열 리소스를 사용하고 있다는 이야기가 나왔다. 거대한 LLM 서비스가 실제로 이런 전용 AI chip 위에서 운영된다는 점이 꽤 인상적이었다.
Trainium2 아키텍처를 보는 관점
Trainium2 설명에서는 칩 내부를 세세하게 외우는 것보다, 어떤 자원이 어떤 역할을 하는지 top-view로 보는 게 중요해 보였다.
큰 흐름은 다음과 같이 이해했다.
- NeuronCore는 실제 tensor 연산을 처리하는 핵심 실행 단위이다.
- HBM(High Bandwidth Memory, 고대역폭 메모리)은 모델 가중치, activation(활성값), KV cache 같은 큰 데이터를 담는 메모리이다.
- DMA(Direct Memory Access, 직접 메모리 접근)와 communication 경로는 메모리와 연산 장치 사이의 데이터 이동을 담당한다.
- 여러 NeuronCore를 묶어 tensor parallelism(텐서 병렬화) 형태로 모델을 나눠 실행할 수 있다.
- EFA(Elastic Fabric Adapter, AWS의 고성능 네트워크 어댑터) 같은 네트워크 연결은 여러 장비로 확장할 때 중요해진다.

LLM 추론에서는 결국 연산 장치가 쉬지 않게 데이터를 공급하는 것이 중요하다. 그래서 뒤쪽 성능 최적화 설명도 계속 memory, communication, compute의 균형으로 이어졌다.
Neuron 환경과 모델 준비 흐름
실제 사용 흐름은 생각보다 명확했다.
모델을 준비하는 단계는 대략 다음과 같았다.
- Hugging Face Hub 등에서 사용할 모델을 선택한다.
- 필요하면 quantization을 적용한다.
- Neuron Compiler로 Trainium의 NeuronCore에 맞게 compile한다.
- vLLM 같은 LLM serving framework를 이용해 모델을 배포한다.
- 추론 성능을 측정하고 병목을 찾는다.
- NKI(Neuron Kernel Interface, 뉴런 커널 인터페이스) kernel이나 설정 변경으로 최적화한다.

이 중에서 NeuronConfig가 꽤 중요해 보였다. 단순히 모델을 올리는 것에서 끝나는 게 아니라, batch size, sequence length, bucket(미리 컴파일할 길이 구간), tensor parallel size, torch dtype 같은 값들이 compile과 추론 성능에 영향을 준다.
특히 sequence length는 input과 output token 길이를 같이 고려해야 하고, bucket은 미리 compile할 sequence length 구간 목록과 연결된다. LLM 서빙에서는 요청마다 길이가 다르기 때문에, 이런 설정을 어떻게 잡느냐가 실제 성능과 비용에 영향을 줄 수 있겠다는 생각이 들었다.
Native PyTorch가 인상적이었던 이유
개인적으로 가장 좋았던 부분은 Native PyTorch 설명이었다.
기존에는 Trainium을 쓰려면 GPU용 PyTorch 코드에서 XLA(Accelerated Linear Algebra, 가속 선형대수) backend, lazy execution, device 설정, NKI 통합 제한 같은 부분을 신경 써야 했던 것으로 보인다. 그런데 새 방식에서는 일반 PyTorch 코드에 가깝게 유지하면서 device를 neuron으로 바꾸는 방향을 강조했다.

이게 중요한 이유는 AI chip을 쓰는 진입 장벽을 낮추기 때문이다. 성능 최적화가 아무리 좋아도 코드 변경량이 너무 크면 실제 팀에서 도입하기 어렵다. 반대로 PyTorch의 고수준 추상화는 유지하면서, 필요한 부분에서 Neuron runtime과 compiler가 최적화해준다면 훨씬 현실적인 선택지가 된다.
내 메모에 “저수준 커널 최적화(NKI)와 파이토치 고수준 추상화(Native PyTorch)를 동시에 잡았음”이라고 적어뒀는데, 이 세션의 핵심 느낌이 딱 그랬다.
LLM 추론 성능 지표
LLM 추론 성능을 볼 때는 단순히 “초당 몇 token”만 보면 부족하다. 세션에서 나온 지표들은 다음과 같이 정리할 수 있다.
| 지표 | 의미 |
|---|---|
| TTFT | Time To First Token, 첫 토큰까지의 시간이다. 요청 후 첫 token이 나오기까지 걸리는 시간이다. |
| ITL | Inter Token Latency, 토큰 간 지연 시간이다. 이후 token들이 생성되는 간격이다. |
| E2E Latency | End-to-End Latency, 종단간 지연 시간이다. 요청부터 최종 응답 완료까지 전체 시간이다. |
| Throughput | 단위 시간당 처리량이다. 보통 tokens/sec 또는 requests/sec 관점에서 본다. |
TTFT는 사용자가 “응답이 시작됐다”고 느끼는 시점과 관련이 있다. ITL은 답변이 얼마나 부드럽게 이어지는지와 관련이 있다. E2E latency는 전체 응답 완료 시간을 보고, throughput은 동시에 얼마나 많은 요청을 처리할 수 있는지를 본다.
LLM 서비스에서는 이 지표들이 서로 trade-off를 가진다. batch size를 키우면 throughput은 좋아질 수 있지만, 개별 요청의 latency가 나빠질 수 있다. sequence length가 길어지면 KV cache가 커지고 memory pressure도 커진다.
그래서 성능 측정은 단일 숫자가 아니라 여러 지표를 같이 봐야 한다.
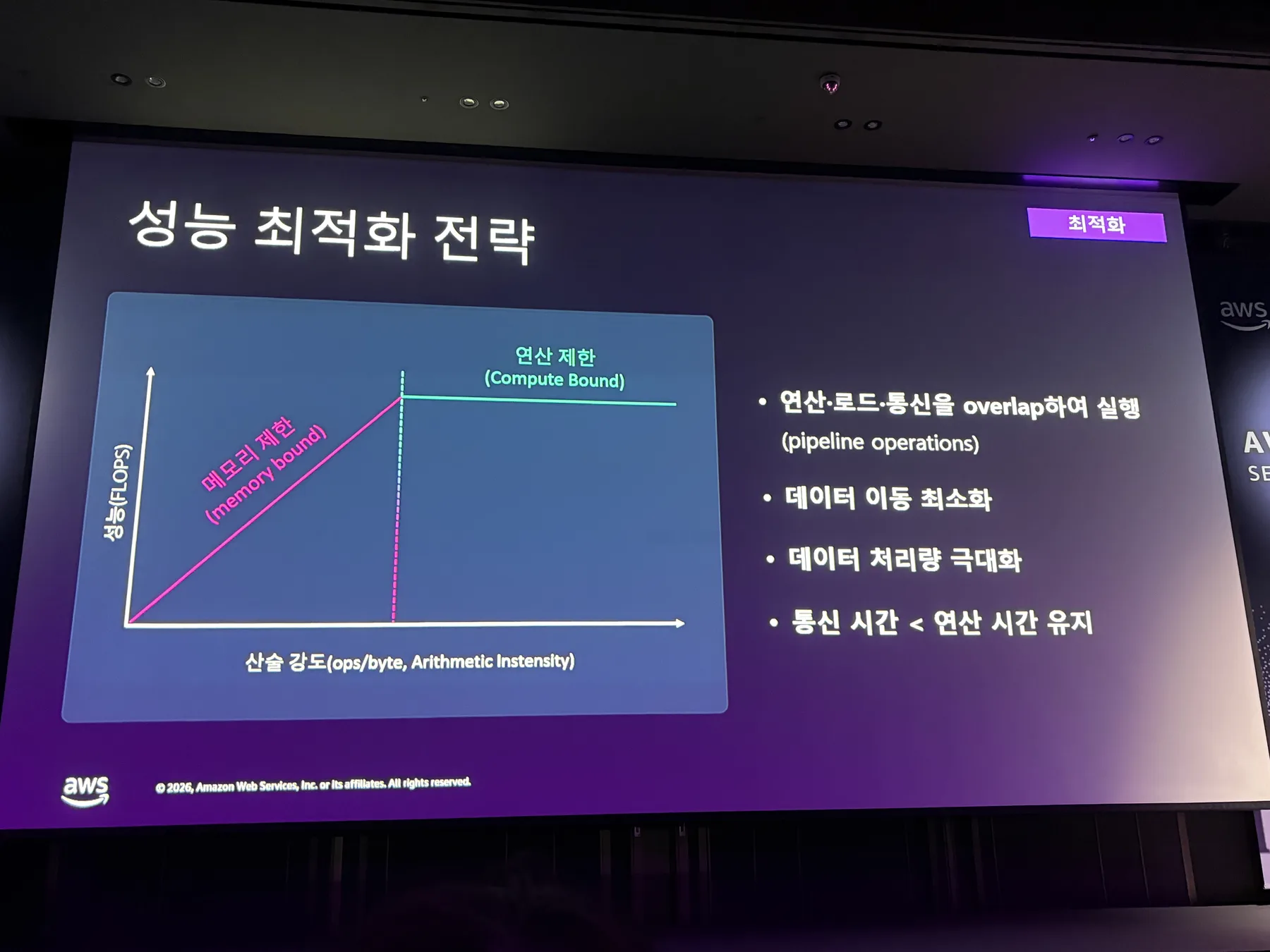
성능 최적화 = 메모리 제한에서 연산 제한으로
성능 최적화 전략에서 가장 기억에 남은 표현은 memory bound(메모리 제한 상태)에서 compute bound(연산 제한 상태)로 옮겨가는 흐름이었다.

이 그림을 보면서 성능 최적화가 왜 단순히 “더 빠른 연산” 문제가 아닌지 더 명확해졌다. 위쪽으로 갈수록 메모리는 작지만 빠르고, 아래쪽으로 갈수록 크지만 상대적으로 느리다. 따라서 자주 쓰는 데이터를 어디에 둘지, 언제 옮길지, 얼마나 자주 재사용할지가 성능에 직접 연결된다.
여기서 SBUF는 NeuronCore 안에 있는 software-managed on-chip SRAM 버퍼로 이해하면 된다. HBM보다 용량은 훨씬 작지만 훨씬 빠르기 때문에, kernel이 실제로 자주 접근하는 데이터를 임시로 올려두는 공간에 가깝다.
PSUM은 partial sum, 즉 중간 누산 결과를 위한 더 작은 on-chip buffer로 보면 된다. 행렬곱이나 attention 연산처럼 여러 번의 곱셈과 덧셈이 쌓이는 연산에서는 중간 합을 빠르게 보관하고 다시 사용하는 공간이 필요하다. PSUM은 그런 누산 결과를 HBM까지 왕복시키지 않도록 돕는 역할에 가깝다.
LLM 추론은 많은 경우 연산 자체보다 데이터 이동이 병목이 될 수 있다. 특히 weight, activation, KV cache가 메모리 계층 사이를 이동하면서 생기는 비용이 크다.
세션에서는 다음 방향이 강조되었다.
- 연산, load, 통신을 overlap한다.
- 불필요한 데이터 이동을 줄인다.
- 데이터 처리량을 극대화한다.
- 통신 시간이 연산 시간보다 작게 유지되도록 한다.
즉 핵심은 NeuronCore가 기다리는 시간을 줄이는 것이다. 아무리 연산 장치가 빨라도 데이터가 늦게 도착하면 전체 성능은 memory bandwidth에 묶인다. 그래서 효율적인 KV cache 관리와 memory hierarchy 이해가 중요해진다.
KV Cache를 다시 보게 됐다
KV cache는 LLM inference에서 이미 알고 있던 개념이지만, 이번 세션을 들으면서 훨씬 현실적인 자원 문제로 느껴졌다.
Transformer decoder는 이전 token들의 key, value를 cache해두고 다음 token 생성 때 재사용한다. 덕분에 매번 전체 sequence를 다시 계산하지 않아도 된다. 하지만 요청 수가 많아지고 sequence length가 길어지면 KV cache가 매우 커진다.
그래서 모델 가중치만 보고 “이 정도면 메모리에 올라가겠지”라고 생각하면 부족하다. 실제 inference serving에서는 batch size, concurrent request 수, input/output length, KV cache 정책까지 같이 봐야 한다.
세션에서 memory bandwidth와 KV cache가 계속 언급된 이유도 여기에 있다고 느꼈다.
NKI Kernel과 성능 비교
마지막 데모 흐름에서는 NKI Attention kernel을 적용하기 전과 후의 성능 비교가 있었다.
NKI는 Neuron Kernel Interface, 즉 NeuronCore에 맞는 kernel을 더 낮은 수준에서 작성하거나 최적화하는 쪽에 가까운 도구로 이해했다.
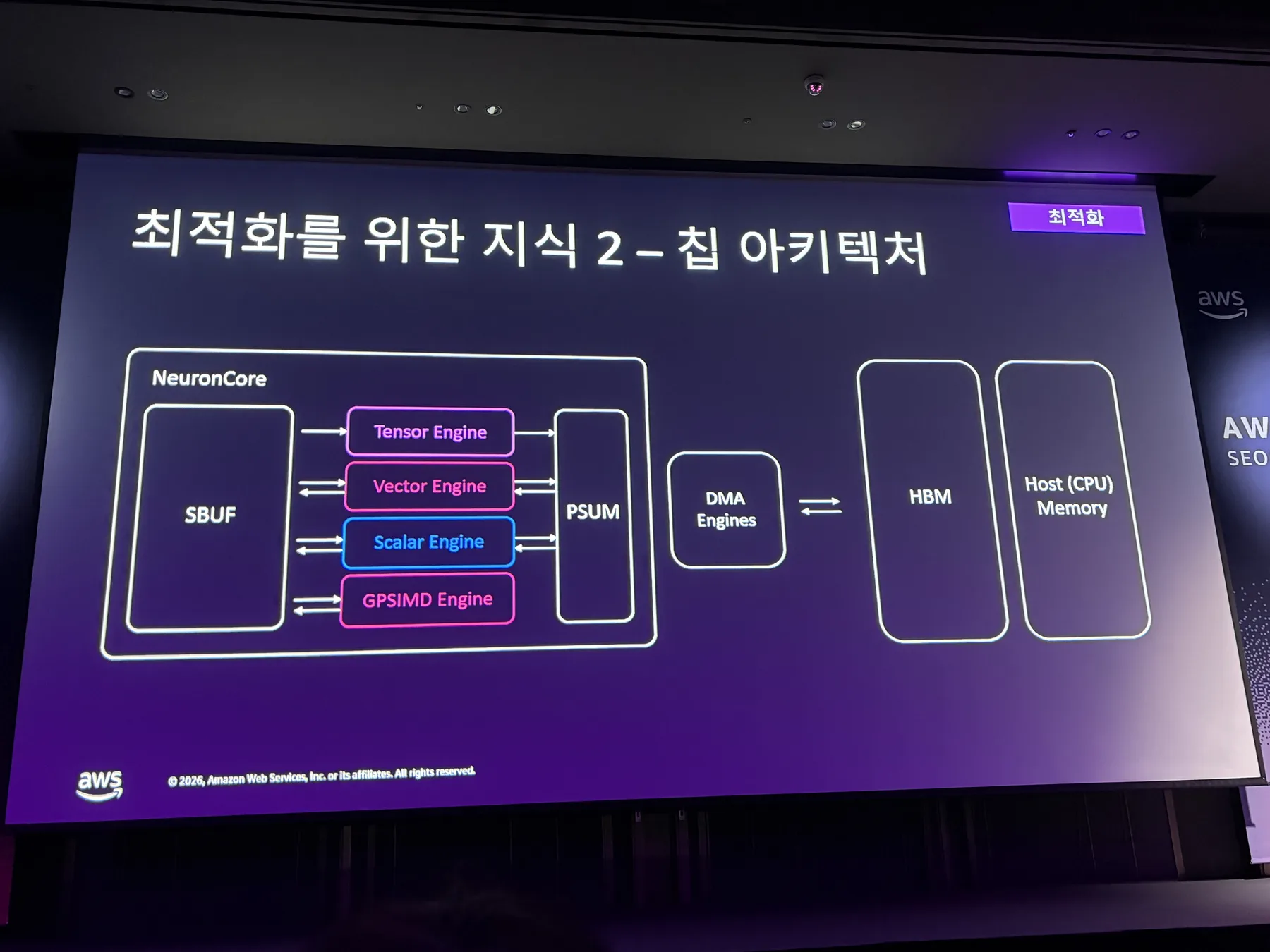
이 부분은 너무 깊게 들어가면 칩 내부 구조 설명이 되어버리지만, top-view로는 “연산 엔진이 있고, 그 주변에 빠른 on-chip memory가 있으며, HBM과 Host Memory 사이의 데이터 이동을 잘 관리해야 한다” 정도로 이해했다. NKI는 이런 구조를 더 직접적으로 의식하면서 kernel을 최적화할 수 있게 해주는 도구에 가깝다.
여기서 좋았던 점은 추상화 수준이 하나만 있는 게 아니라는 점이다.
일반적인 모델 개발자는 Native PyTorch와 vLLM을 통해 비교적 높은 수준에서 접근할 수 있다. 반면 성능이 정말 중요한 부분은 NKI를 통해 더 낮은 수준까지 내려가 최적화할 수 있다.
즉 사용성은 PyTorch 쪽에서 확보하고, 성능 병목은 NKI 쪽에서 잡는 구조이다.
짧은 감상
이 세션이 기억에 남은 이유는 “LLM 추론을 잘한다”는 말이 생각보다 많은 층위를 가진다는 걸 보여줬기 때문이다.
모델을 고르고 배포하는 것만으로 끝나지 않는다. Neuron SDK, vLLM, compile 설정, quantization, tensor parallelism, KV cache, memory bandwidth, TTFT, ITL, throughput까지 이어진다.
내가 평소에 애플리케이션 레벨에서 AI API를 호출할 때는 이런 부분을 거의 직접 보지 않는다. 하지만 실제로 거대한 모델을 안정적으로 서빙하려면 아래쪽 인프라와 칩 특성까지 이해해야 한다는 점이 새삼 크게 느껴졌다.
특히 “고수준 PyTorch 추상화와 저수준 NKI 최적화를 동시에 가져간다”는 방향이 좋았다. 추론 인프라는 결국 사용성과 성능 중 하나만 잡아서는 오래가기 어렵기 때문이다.
AWS Summit 2026의 마지막 세션으로 듣기에 꽤 좋았다. 기술적으로 너무 깊게 파고들면 어려울 수 있는 주제였지만, 전체 흐름을 따라가며 LLM inference stack을 한 번에 보는 느낌이 있었다. 나중에 Neuron SDK나 vLLM 기반 serving을 직접 만져볼 일이 생기면 이 세션 내용을 다시 떠올리게 될 것 같다.
나는 왜 하이닉스를 13만원에 사서 28만원에 팔았는가. HBM이 안들어가는데가 없네..